사람인에 있는 공고들을 크롤링 해오려고 한다.
jobscrapper라는 폴더를 하나 만들고 main.go 파일을 하나 만들었다.
Add baseURL
var baseURL string = "https://www.saramin.co.kr/zf_user/search/recruit?&searchword=python"Add getPages()
func main() {
getPages()
}
func getPages() int {
res, err := http.Get(baseURL)
checkErr(err)
checkStatusCode(res)
return 0
}
func checkErr(err error) {
if err != nil {
log.Fatalln(err)
}
}
func checkStatusCode(res *http.Response) {
if res.StatusCode != 200 {
log.Fatalln("Request failed with Status:", res.StatusCode, res.Status)
}
}처음에 indeed에서 크롤링을 막아놓아서 그런지 http.Get(url) 방법으로는 403 에러가 발생했다. User-Agent와 프록시로 해봤지만, 해결되지 않았고 사람인 페이지로 대체했다.
ADD>
이후에 찾아보니 indeed에서 크롤링하는 것을 indeed 측에서 막았다. http://www.indeed.com/robots.txt를 확인해보면, Disallow했다. robots.txt를 알고싶은 사람은 링크를 통해 글을 읽어보면 좋겠다.
go query라는 별도의 라이브러리를 추가해주자. 참고로 위의 error 처리는 go query에 적혀있는 방식을 보고 따라했다.
터미널에서 아래 명령어를 실행해주자.
go get github.com/PuerkitoBio/goquery
Add go query
func getPages() int {
...
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
checkErr(err)
fmt.Println(doc)
...
}
별도의 문제없이 성공이 되고 응답이 오는 모습이다.
참고!
checkErr()나 checkStatusCode()라는 함수를 통해 에러를 처리했다. 이와같은 방식은 함수 명을 통하여 의미를 부여할 수 있지만 코드가 길어지는 경우 어떻게 에러를 처리하는지 확인하고 싶을 때, depth가 한번 더 들어가있기 때문에 가독성이 떨어질 수 있다. 상황에 따라서 똑똑하게 사용하자!
go query는 github에서 잘 읽어보면 사용방법이 나와있다.
// Find the review items
doc.Find(".left-content article .post-title").Each(func(i int, s *goquery.Selection) {
// For each item found, get the title
title := s.Find("a").Text()
fmt.Printf("Review %d: %s\n", i, title)
})div class 이름을 Find 안에 적어주고 적혀있는 내용을 가져올 수 있다.

페이지의 개수를 알고싶기 때문에 페이지를 나타내는 div의 class네임인 pagination을 개발자 도구탭에서 찾아냈다.
doc, err := goquery.NewDocumentFromReader(res.Body)
checkErr(err)
doc.Find(".pagination").Each(func(i int, s *goquery.Selection) {
fmt.Println(s.Html())
})
이렇게 안에 적힌 페이지의 개수를 가져올 수 있다.
a href에 적힌 #recruit_info는 현재 페이지를 나타내는 듯 하다.
doc.Find(".pagination").Each(func(i int, s *goquery.Selection) {
fmt.Println(s.Find("a").Length())
})a의 개수를 출력해 본 결과 10개로 정확하게 나온다.
https://www.saramin.co.kr/zf_user/search/recruit?=&searchword=python&recruitPage=2&recruitPageCount=50
크롤링 하는 방법은 아래와 같다.
- 원하는 검색 키워드를 searchword에 넣어준다.
- 원하는 페이지 번호를 recruitPage에 넣어준다. (공고를 가져오기 위함)
- 원하는 페이지 공고 개수를 recruitCount에 넣어준다.
일단, getPages는 페이지 개수를 구하기 위한 함수였기 때문에 아래와 같이 수정해준다.
func getPages() int {
pages := 0
res, err := http.Get(baseURL)
checkErr(err)
checkStatusCode(res)
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
checkErr(err)
doc.Find(".pagination").Each(func(i int, s *goquery.Selection) {
pages = s.Find("a").Length()
})
return pages
}페이지들의 개수를 가져오싸으니, 각각 페이지의 공고들을 가져와 보자.
func main() {
total := getPages()
fmt.Println(total)
for i := 1; i <= total; i++ {
getPage(i)
}
}main에서 페이지의 개수들을 getPages()를 통해 가져오고 각각 페이지를 반복문을 통해서 가져온다. 페이지 숫자는 1~total까지 있기때문에 1부터 tatal까지 반복문을 돌려준 모습이다.
func getPage(page int) {
pageURL := baseURL + "&recruitPage=" + strconv.Itoa(page)
fmt.Println("Requesting :", pageURL)
res, err := http.Get(pageURL)
checkErr(err)
checkStatusCode(res)
}https://www.saramin.co.kr/zf_user/search/recruit?&searchword=python&recruitCount=50&recruitPage=10
페이지를 넘기는 방법은 위처럼 recruitPage를 사용하여 페이지 번호를 넘길 수 있다. 기본 URL에 recruitPage 번호를 통해 각각의 모든 공고들을 페이지 번호를 넘겨가며 크롤링할 수 있다.

이제 페이지별로 각 공고들을 크롤링해오기 위해 공고가 해당되는 div class 이름을 가져오자. 사람인의 경우 item_recruit으로 되어있다.
func getPage(page int) {
...
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
checkErr(err)
doc.Find(".item_recruit").Each(func(i int, s *goquery.Selection) {
fmt.Println(s.Html())
})
}getPage 함수에 goquery를 통해 item_recruit에 해당하는 데이터들을 가져오자.

아주 많은 html 코드들이 출력된다. (잘 되고 있군)
doc.Find(".item_recruit").Each(func(i int, s *goquery.Selection) {
id, _ := s.Attr("value")
title := s.Find(".job_tit>a").Text()
condition := s.Find(".job_condition").Text()
fmt.Println(id, title, condition)
})
필요한 정보들만 찾아서 출력해보면 위와 같다.
이제 가져올 수 있는 필요한 정보들을 묶어 struct로 만들자.
type extractedJob struct {
id string
title string
location string
summary string
company string
}그 후, extractJob 함수를 추가해서 struct에 넣어주자.
func getPage(page int) {
...
doc, err := goquery.NewDocumentFromReader(res.Body)
checkErr(err)
doc.Find(".item_recruit").Each(func(i int, card *goquery.Selection) {
extractJob(card)
})
}func claanString(str string) string {
return strings.Join(strings.Fields(strings.TrimSpace(str)), "")
}
func extractJob(card *goquery.Selection ) {
id, _ := card.Attr("value")
title := claanString(card.Find(".job_tit>a").Text())
location := claanString(card.Find(".job_condition>span>a").Text())
summary := claanString(card.Find(".job_sector").Clone().ChildrenFiltered(".job_day").Remove().End().Text())
company := claanString(card.Find(".area_corp>strong>a").Text())
fmt.Println(id, title, location, summary, company)
}
잘 가져오는 모습이다.
func extractJob(card *goquery.Selection ) extractedJob {
id, _ := card.Attr("value")
title := claanString(card.Find(".job_tit>a").Text())
location := claanString(card.Find(".job_condition>span>a").Text())
summary := claanString(card.Find(".job_sector").Clone().ChildrenFiltered(".job_day").Remove().End().Text())
company := claanString(card.Find(".area_corp>strong>a").Text())
return extractedJob {
id : id,
title : title,
location : location,
summary : summary,
company : company,
}
}extractJob을 return 해주도록 수정하자.
func getPage(page int) []extractedJob{
...
var jobs []extractedJob
doc.Find(".item_recruit").Each(func(i int, card *goquery.Selection) {
job := extractJob(card)
jobs = append(jobs, job)
})
return jobs
}getPage도 수정해주자.
func main() {
...
var jobs []extractedJob
for i := 1; i <= total; i++ {
extractedJobs := getPage(i)
jobs = append(jobs, extractedJobs...)
}
}main도 수정해주자.
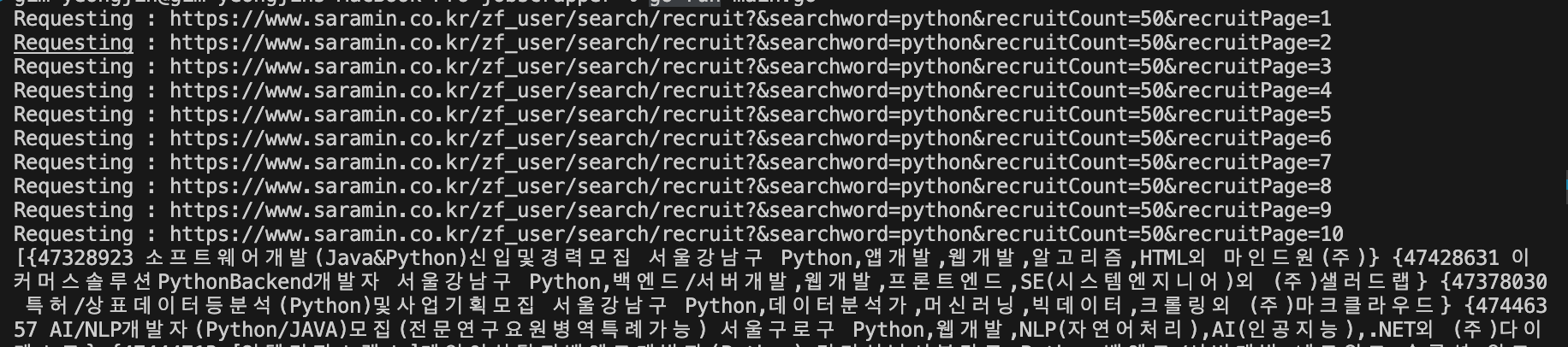
총 10페이지 모두 가져오는 것을 볼 수 있다.
이제 가져온 데이터를 csv파일에 쓸 것이다. 아래 Go Package에서 지원하는 csv package를 사용할 것이다.
csv package - encoding/csv - Go Packages
Discover Packages Standard library encoding csv Version: go1.21.6 Opens a new window with list of versions in this module. Published: Jan 9, 2024 License: BSD-3-Clause Opens a new window with license information. Imports: 8 Opens a new window with list of
pkg.go.dev
사용 예시나 설명은 해당 링크에 자세하게 나와있다.
func writeJobs(jobs []extractedJob) {
file, err := os.Create("jobs.csv")
checkErr(err)
w := csv.NewWriter(file)
defer w.Flush() // must
headers := []string{"Id", "Title", "Location", "Summary", "Company"}
Werr := w.Write(headers)
checkErr(Werr)
for _, job := range(jobs) {
jobSlice := []string{job.id, job.title, job.location, job.summary, job.company}
jobErr := w.Write(jobSlice)
checkErr(jobErr)
}
}해당 라이브러리를 근거로 위와 같이 작성해주었다. 함수가 종료될 때, csv를 쓰도록 defer를 사용했다. 먼저, headers를 작성하여 쓰기 작업을 한 후 jobs의 데이터들을 하나씩 쓰도록 코드를 구현했다. w.Write의 경우 error를 return하기 때문에 error체크도 병행해주었다.


코드를 돌려보면 jobs.csv 파일이 생성되고 쓰기 작업을 한 작업들이 담겨진 모습이다.
CSV Viewer and Editor
Save Your result: .csv or .xlsx EOL: CRLFLF Include Header
www.convertcsv.com
위 페이지에 csv파일에 담겨진 문자열을 전체 복사한 후 붙여넣으면 아래와 같이 보기 좋게 볼 수 있다.

id에 해당하는 값은 해당 공고의 고유 번호이다. 실제로 공고를 눌러서 확인하면 ID값이 연결된 것을 볼 수 있다.
https://www.saramin.co.kr/zf_user/jobs/relay/view?rec_idx=47446357
위는 1번 공고의 id 값으로 연결된 공고 url이다. 여기서 rec_idx가 바로 id 값이다. id를 link로 이어지도록 고쳐보자.
func writeJobs(jobs []extractedJob) {
...
for _, job := range(jobs) {
jobSlice := []string{"https://www.saramin.co.kr/zf_user/jobs/relay/view?rec_idx="+job.id, job.title, job.location, job.summary, job.company}
jobErr := w.Write(jobSlice)
checkErr(jobErr)
}
}writeJobs 함수를 위와 같이 수정해주자.

id값이 위와같이 수정되고, id를 복사해서 웹에 넣어주면 아래와 같이 공고를 확인할 수 있다.
Add
Change id -> link

goroutine 적용
함수들을 보면 goroutine을 사용하면 더 빠르게 동작할 수 있는 함수들이 있음을 느꼈을 수 있다. getPage()와 extractJob() 함수의 경우 goroutine을 사용하면 병렬적으로 보다 빠르게 데이터를 가져올 수 있다.
먼저, getPage()를 고쳐보자. 데이터를 가져와야하기 때문에 channel을 사용한다.
func main() {
total := getPages()
var jobs []extractedJob
c := make(chan []extractedJob)
for i := 1; i <= total; i++ {
go getPage(i, c)
}
for i := 1; i <= total; i++ {
job := <- c
jobs = append(jobs, job...)
// same
// jobs = append(jobs, <- c...)
}
writeJobs(jobs)
}getPage()를 부르는 main()함수에 channel을 생성하고 getPage() 파라미터에 추가해주자.
func getPage(page int, mainC chan <-[]extractedJob) {
pageURL := baseURL + "&recruitPage=" + strconv.Itoa(page)
fmt.Println("Requesting :", pageURL)
res, err := http.Get(pageURL)
checkErr(err)
checkStatusCode(res)
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
checkErr(err)
var jobs []extractedJob
c := make(chan extractedJob)
cards := doc.Find(".item_recruit")
cards.Each(func(i int, card *goquery.Selection) {
job := extractJob(card)
jobs = append(jobs, job)
})
mainC <- jobs
}파라미터를 추가하고, return을 없앤 뒤 jobs를 채널에 전송하자.
이제 extractJob() 함수에 goroutine을 추가해보자. 위 getPage() 함수에서 채널을 만든 뒤, extractJob 파라미터에 추가하자.
func getPage(page int, mainC chan <-[]extractedJob) {
pageURL := baseURL + "&recruitPage=" + strconv.Itoa(page)
fmt.Println("Requesting :", pageURL)
res, err := http.Get(pageURL)
checkErr(err)
checkStatusCode(res)
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
checkErr(err)
var jobs []extractedJob
c := make(chan extractedJob)
cards := doc.Find(".item_recruit")
cards.Each(func(i int, card *goquery.Selection) {
go extractJob(card, c)
})
for i:=0; i< cards.Length(); i++ {
job := <- c
jobs = append(jobs, job)
}
mainC <- jobs
}func extractJob(card *goquery.Selection, c chan<- extractedJob) {
link, _ := card.Attr("value")
title := claanString(card.Find(".job_tit>a").Text())
location := claanString(card.Find(".job_condition>span>a").Text())
summary := claanString(card.Find(".job_sector").Clone().ChildrenFiltered(".job_day").Remove().End().Text())
company := claanString(card.Find(".area_corp>strong>a").Text())
c <- extractedJob {
link : link,
title : title,
location : location,
summary : summary,
company : company,
}
}extractJob에서 파라미터를 추가하고, return을 없앤 뒤 채널에 추출한 extractJob을 전송하면 된다.


goroutine 사용 전 후를 비교해보면 recruitPage의 순서가 다르다는 것을 볼 수 있다. goroutine을 사용하여 병렬적으로 수행했기 때문이다. 프로그램을 돌려보면 이전보다 확실히 빠르다는 것을 느낄 수 있다. 체감상 2~3배 정도 빨라진 것 같다.
Add echo server
현재는 python으로만 검색하여 공고들을 스크랩했지만, python을 동적으로 변경하여 입력한 기술스택으로 공고를 수집할 수 있도록 만들어보자. go에서는 다양한 웹 프레임워크가 존재한다. echo는 그 중 성능이 뛰어난 것으로 알고 있다. echo web framework를 통해 동적으로 스크랩할 수 있도록 구현해보려한다.

일단, 기존 main.go에 있던 코드들을 scrapper directory안 scrapper.go로 이동시켜주었다. main() 함수를 Scrape()이라는 함수로 변경하고 string 파라미터를 추가하여 python을 대체할 문자열을 받을 수 있도록 했다. 첫 문자를 대문자로 한 이유는 export하기 위함이다. main()에서 접근하기 위함! 변경된 코드는 아래와 같다.
package scrapper
import (
"encoding/csv"
"fmt"
"log"
"net/http"
"os"
"strconv"
"strings"
"github.com/PuerkitoBio/goquery"
)
type extractedJob struct {
link string
title string
location string
summary string
company string
}
// Scrape saramin by a term
func Scrape(term string) {
var baseURL string = "https://www.saramin.co.kr/zf_user/search/recruit?&searchword="+term+"&recruitCount=50"
total := getPages(baseURL)
var jobs []extractedJob
c := make(chan []extractedJob)
for i := 1; i <= total; i++ {
go getPage(i, baseURL, c)
}
for i := 1; i <= total; i++ {
job := <- c
jobs = append(jobs, job...)
// same
// jobs = append(jobs, <- c...)
}
writeJobs(jobs)
}
func writeJobs(jobs []extractedJob) {
file, err := os.Create("jobs.csv")
checkErr(err)
w := csv.NewWriter(file)
defer w.Flush() // must
headers := []string{"Link", "Title", "Location", "Summary", "Company"}
Werr := w.Write(headers)
checkErr(Werr)
for _, job := range(jobs) {
jobSlice := []string{"https://www.saramin.co.kr/zf_user/jobs/relay/view?rec_idx="+job.link, job.title, job.location, job.summary, job.company}
jobErr := w.Write(jobSlice)
checkErr(jobErr)
}
}
func getPage(page int, baseURL string, mainC chan <-[]extractedJob) {
pageURL := baseURL + "&recruitPage=" + strconv.Itoa(page)
fmt.Println("Requesting :", pageURL)
res, err := http.Get(pageURL)
checkErr(err)
checkStatusCode(res)
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
checkErr(err)
var jobs []extractedJob
c := make(chan extractedJob)
cards := doc.Find(".item_recruit")
cards.Each(func(i int, card *goquery.Selection) {
go extractJob(card, baseURL, c)
})
for i:=0; i< cards.Length(); i++ {
job := <- c
jobs = append(jobs, job)
}
mainC <- jobs
}
func claanString(str string) string {
return strings.Join(strings.Fields(strings.TrimSpace(str)), "")
}
func extractJob(card *goquery.Selection, baseURL string, c chan<- extractedJob) {
link, _ := card.Attr("value")
title := claanString(card.Find(".job_tit>a").Text())
location := claanString(card.Find(".job_condition>span>a").Text())
summary := claanString(card.Find(".job_sector").Clone().ChildrenFiltered(".job_day").Remove().End().Text())
company := claanString(card.Find(".area_corp>strong>a").Text())
c <- extractedJob {
link : link,
title : title,
location : location,
summary : summary,
company : company,
}
}
func getPages(baseURL string) int {
pages := 0
res, err := http.Get(baseURL)
checkErr(err)
checkStatusCode(res)
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
checkErr(err)
doc.Find(".pagination").Each(func(i int, s *goquery.Selection) {
pages = s.Find("a").Length()
})
return pages
}
func checkErr(err error) {
if err != nil {
log.Fatalln(err)
}
}
func checkStatusCode(res *http.Response) {
if res.StatusCode != 200 {
log.Fatalln("Request failed with Status:", res.StatusCode, res.Status)
}
}
main을 추가하고 python string을 보내 테스트해보자.
package main
import "github.com/qazyj/jobscrapper/scrapper"
func main() {
scrapper.Scrape("python")
}(잘 돌아간다!)
이제 main에 echo를 사용할 코드를 추가해보자! 아래 링크를 참고했다.
GitHub - labstack/echo: High performance, minimalist Go web framework
High performance, minimalist Go web framework. Contribute to labstack/echo development by creating an account on GitHub.
github.com
go get github.com/labstack/echo
명령어를 터미널에 쳐주자.
예제대로 main에 코드를 추가 했다. (middleware는 사용하지 않을 것이기때문에 추가해주지 않았다.)
package main
import (
"net/http"
"github.com/labstack/echo"
)
func main() {
// Echo instance
e := echo.New()
// Routes
e.GET("/", hello)
// Start server
e.Logger.Fatal(e.Start(":1323"))
}
// Handler
func hello(c echo.Context) error {
return c.String(http.StatusOK, "Hello, World!")
}1323포트 번호로 서버를 열었다.

테스트해보면 위와같이 문제없이 돌아가는 것을 확인할 수 있다.
참고!
server를 종료하고자 한다면 mac기준 control+c를 누르면 된다.
이제 검색어를 입력할 수 있는 input box와 button이 있는 페이지를 만들어보자.
html 추가
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>Go Jobs</title>
</head>
<body>
<h1>Go Jobs</h1>
<h3>www.saramin.co.kr scrapper</h3>
<form method="POST" action="/scrape">
<input placeholder="what job do you want" name="term" />
<button>Search</button>
</form>
</body>
</html>이제 메인에서 handler를 통해 localhost:1323으로 주소를 입력할 때 home.html이 나올 수 있도록 만들어주자.
func main() {
// Echo instance
e := echo.New()
// Routes
e.GET("/", handleHome) //Add
// Start server
e.Logger.Fatal(e.Start(":1323"))
}
// Add
func handleHome(c echo.Context) error {
return c.File("home.html")
}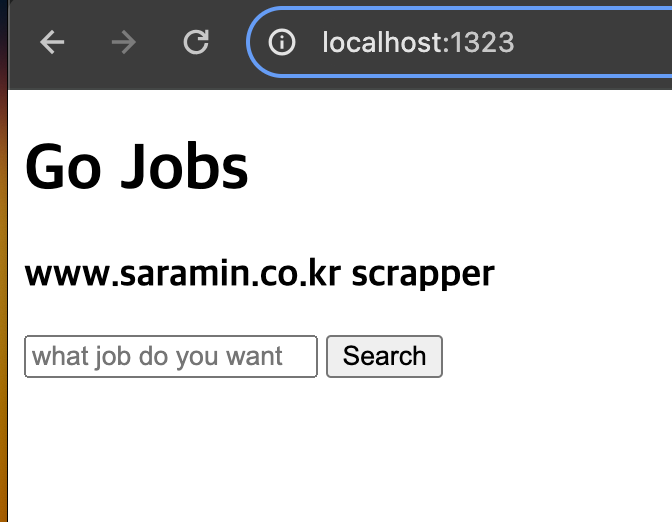
잘 나온다.
이제 Search 버튼을 누르면 동작할 POST method를 추가해보자.
func main() {
...
e.POST("/scrape", handlerScrape)
...
}
func handlerScrape(c echo.Context) error {
fmt.Println(c.FormValue("term"))
return nil
}그 후 돌려보면 아래와 같이 검색한 검색어가 정상적으로 들어오는 것을 확인할 수 있다.

이제 csv를 다운로드할 수 있도록 구현해볼 것이다.
const fileName string = "jobs.csv"
func handlerScrape(c echo.Context) error {
defer os.Remove(fileName)
term := strings.ToLower(scrapper.CleanString(c.FormValue("term")))
scrapper.Scrape(term)
return c.Attachment(fileName, fileName)
}handlerScrape 함수를 위와 같이 작성해주었따. scrapper에 term을 파라미터로 보내 jobs.csv를 만들고 해당 csv 파일이 바로 다운로드 되도록 구현했다. 해당 함수가 종료되면 jobs.csv는 삭제되도록 defer를 사용했다.
Reference
'Go' 카테고리의 다른 글
| URL Checker & Go Routine (0) | 2024.01.14 |
|---|---|
| method를 활용한 map 구현(Search, Add, Delete, Update) (0) | 2024.01.10 |
| struct/public,private/String()/error handling (0) | 2024.01.07 |
| Struct (0) | 2024.01.04 |
| Maps (0) | 2023.12.30 |