- 코드
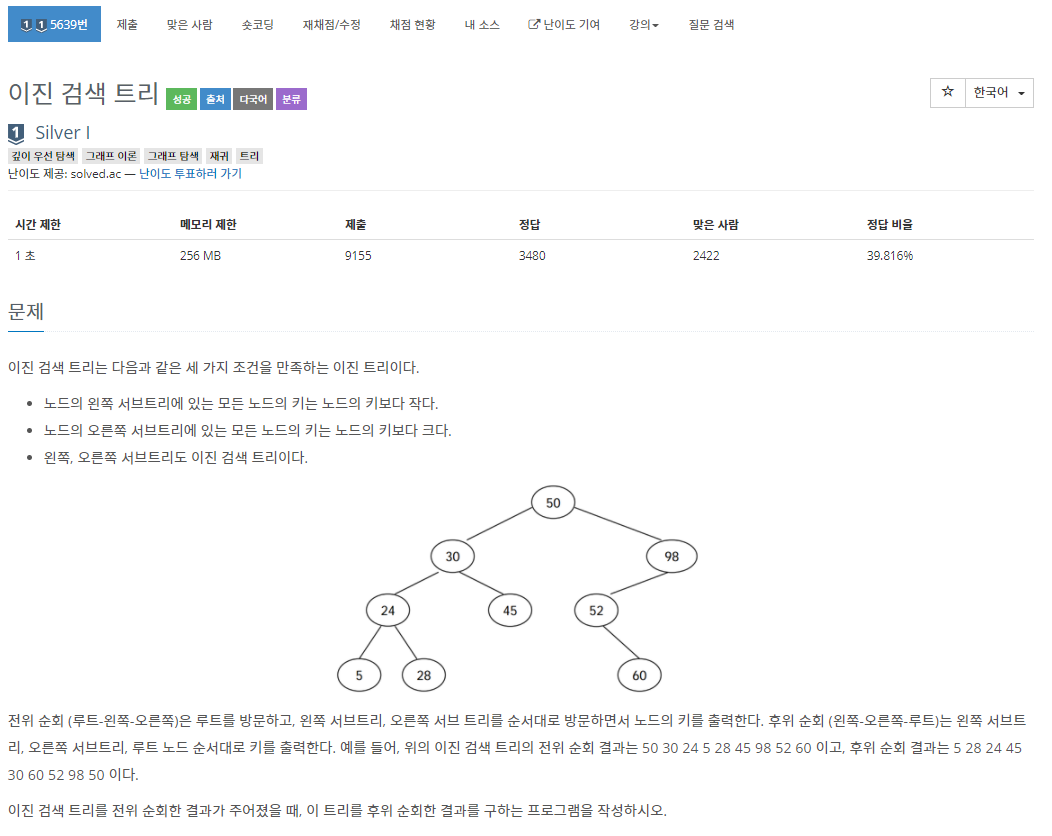
정답 코드 : Node 클래스를 이진 검색 트리에 맞게 left, right, value를 선언해서 사용했다. 기준 노드보다 삽입 노드의 숫자가 작은 경우 왼쪽, 큰 경우 오른쪽으로 재귀 호출하며 삽입하였고, 출력은 (왼쪽-오른쪽-루트) 순서로 노드를 방문하며 출력하였다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class Main {
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
Node node = new Node(N);
String s;
while ((s = br.readLine()) != null) {
N = Integer.parseInt(s);
node = InsertNode(node, N);
}
PostOrder(node);
}
private static Node InsertNode(Node node, int N) {
Node newNode = null;
if (node == null) return new Node(N);
if (node.value > N) {
newNode = InsertNode(node.left, N);
node.left = newNode;
}
else {
newNode = InsertNode(node.right, N);
node.right = newNode;
}
return node;
}
private static void PostOrder(Node node) {
if (node != null) {
PostOrder(node.left);
PostOrder(node.right);
System.out.println(node.value);
}
}
private static class Node {
Node left;
Node right;
int value;
public Node(int value) {
this.value = value;
}
}
}'algorithm' 카테고리의 다른 글
| [JAVA] NHN 모의시험 문제 (0) | 2020.10.23 |
|---|---|
| [JAVA] 백준 11049번 : 행렬 곱셈 순서 (0) | 2020.10.22 |
| [JAVA] 백준 2437번 : 저울 (0) | 2020.10.16 |
| [JAVA] 백준 : 1759번 : 암호 만들기 (0) | 2020.10.14 |
| [JAVA] 백준 16916번 : 부분 문자열 (0) | 2020.10.13 |