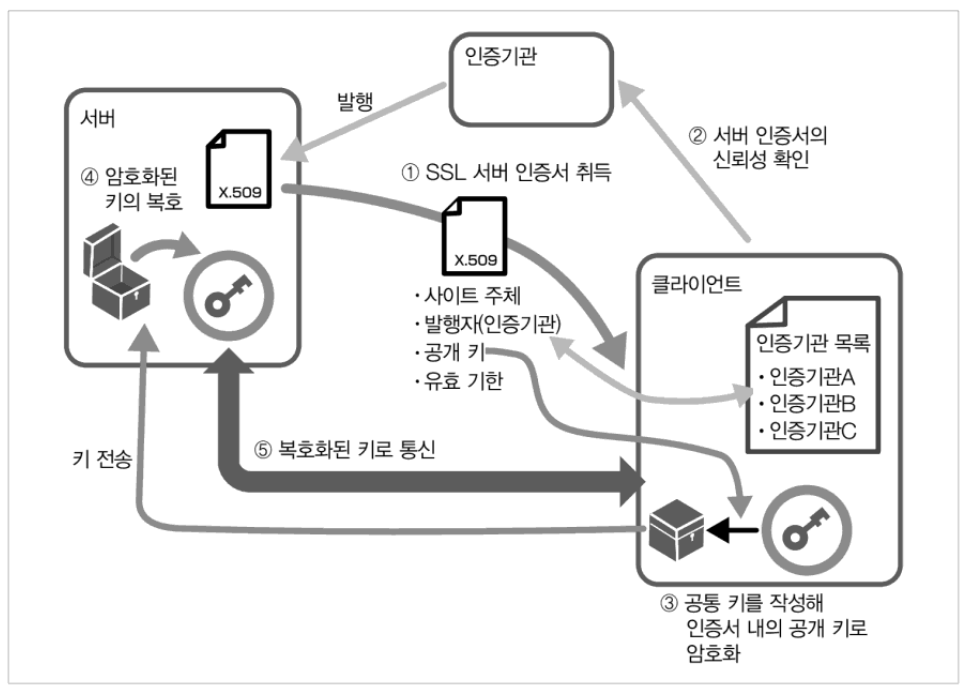
이전에 배운 몇 가지 기능을 Go 언어로 표현해보자. 이전에 배운 내용을 재확인하며, 이해를 돕는 용도이다.
1.0 Keep-Alive
Go 언어의 HTTP API는 아무 설정을 하지 않더라도 기본으로 Keep-Alive가 유효하다. 따라서 올바르게 통신이 완료된 뒤에도 세션이 유지되도록 되어 있다. 단 그렇게 되려면 클라이언트 코드 쪽에서 반드시 response.Body를 끝까지 다 읽고난 후에 닫아야 한다고 도큐먼트에 명시돼 있다(Link). 소켓이라는 하나의 파이프를 시분할로 공유하는 시스템이므로 끝까지 다 읽고 종료했다는 사실을 명시하지 않으면, 다음 작업을 언제 시작해야 할지 판단할 수 없기때문에 재이용할 수 없다. response.Body()에는 바로 전의 HTTP 접속이 성공하지 않았을 땐 nil이 저장되지만, 성공했을 때는 예를 들면 Content-Length: 0으로 바디가 비어 있을 때도 반드시 io.Reader의 실체가 들어가므로, 오류 시 외는 모두 읽어야만 한다.
Keep-Alive를 위해 바디를 모두 읽는다. 코드는 아래와 같다.
resp, err := http.Get("http://www.naver.com")
if err != nil {
panic(err)
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
2.0 TLS
Go 언어는 표준 라이브러리를 사용한 TLS 통신(https)이 가능하다. Go 언어의 표준 라이브러리는 openssl 등의 라이브러리를 이용하는 것이 아니라 밑바닥부터 만든 Go 언어의 코드를 사용한다. 이를 직접 구현해보자.
2.1 인증서 만들기
기본적으로는 시스템이 가진 인증서를 사용해 인증서를 확인한다.
하나의 인증서를 만드는 기본 흐름은 아래와 같다.
- OpenSSL 커맨드로 비밀 키 파일을 만든다.
- 인증서 요청 파일을 만든다.
- 인증서 요청 파일에 서명해서 인증서를 만든다.
보통 인증서 요청까지는 필요로 하는 사람이 작성한 후 인증기관에서 유료로 서명을 받는다. 하지만, 이번은 테스트 목적이기 때문에 스스로 서명할 것이다. 참고로, 자기 서명 인증서는 통신 경로 은닉화에는 사용할 수 있지만 서버의 신원 보증에는 안된다. 각 컴퓨터에 설치하면 수동으로 믿을 수 있는 인증서라고 가르칠 수 있다.
우선은 openssl.cnf 파일을 복사해 설정을 변경한다. 커맨드라인만으로는 설정할 수 없는 항목이 있기때문에 설정 파일 편집이 필요하다. openssl.cnf 파일의 템플릿은 /etc/local/openssl/openssl.cnf와 /etc/ssl/openssl.cnf, C:\OpenSSL\bin\openssl.cnf에 있다. 인증기관, 서버, 클라이언트의 세 가지 인증서 작성을 위한 설정을 끝에 추가한다. OpenSSL 설정 파일은 아래와 같다.
[CA]
basicConstraints=critical,CA:TRUE,pathlen:0
keyUsage=digitalSignature,keyCertSign,cRLSign
[Server]
basicConstraints=CA:FALSE
keyUsage=digitalSignatrue,dataEncipherment
extendedKeyUsage=serverAuth
[Client]
basicConstraints=CA:FALSE
keyUsage=digitalSignature,dataEncipherment
extendedKeyUsage=clientAuth
OpenSSL의 권장 설정 항목
[req_distinguished_name]
# 기본 국가 코드
countryName_default = KR
# 기본 도/주
stateOrProvinceName_default = Incheon
# 기본 도시명
localityName_default = namdong
# 기본 조직명
0.organizationName_default = example.com
# 기본 관리자 메일 주소
emailAddress = qazyj@exampe.com
모두 작성하면 아래와 같다.
# openssl.cnf
[ req ]
default_bits = 2048
default_keyfile = privkey.pem
distinguished_name = req_distinguished_name
req_extensions = req_ext
x509_extensions = v3_ca
[ req_distinguished_name ]
countryName = Country Name (2 letter code)
# 기본 국가 코드
countryName_default = KR
stateOrProvinceName = State or Province Name (full name)
# 기본 도/주
stateOrProvinceName_default = Incheon
localityName = Locality Name (eg, city)
# 기본 도시명
localityName_default = namdong
organizationName = Organization Name (eg, company)
# 기본 조직명
organizationName_default = example.com
commonName = Common Name (e.g. server FQDN or YOUR name)
commonName_max = 64
# 기본 관리자 메일 주소
emailAddress = qazyj@exampe.com
[ req_ext ]
subjectAltName = @alt_names
[ v3_ca ]
subjectAltName = @alt_names
[ alt_names ]
DNS.1 = localhost
DNS.2 = example.com
[CA]
basicConstraints=critical,CA:TRUE,pathlen:0
keyUsage=digitalSignature,keyCertSign,cRLSign
[Server]
basicConstraints=CA:FALSE
keyUsage=digitalSignatrue,dataEncipherment
extendedKeyUsage=serverAuth
[Client]
basicConstraints=CA:FALSE
keyUsage=digitalSignature,dataEncipherment
extendedKeyUsage=clientAuth
아래와 같이 루트 인증기관 인증서를 작성하자.
# RSA 2048 비트 비밀 키 생성
$ openssl genrsa -out ca.key 2048
# 인증서 서명 요청(CSR) 작성
$ openssl req -new -sha256 -key ca.key -out ca.csr -config openssl.cnf
# 인증서를 자신의 비밀 키로 서명해서 생성
$ openssl x509 -in ca.csr -days 365 -req -signkey ca.key -sha256 -out ca.crt -extfile ./openssl.cnf -extensions CA
모두 다 하고나면 아래와 같이 4개의 파일이 있다.

각 과정에서 생성된 파일을 확인하려면 아래 명령어로 확인할 수 있다.
# 비밀 키 확인
$ openssl rsa -in ca.key -text
# 인증서 서명 요청(CSR) 확인
$ openssl req -in ca.csr -text
# 인증서 확인
$ openssl x509 -in ca.crt -text
다음으로 아래 순서대로 서버의 인증서를 작성하자.
# RSA 2048 비트 비밀 키 생성
$ openssl genrsa -out server.key 2048
# 인증서 서명 요청(CSR) 작성
$ openssl req -new -nodes -sha256 -key server.key -out server.csr -config openssl.cnf
# 인증서를 자신의 비밀 키로 서명해서 생성
$ openssl x509 -req -days 365 -in server.csr -sha256 -out server.crt -CA ca.crt -CAkey ca.key -CAcreateserial -extfile ./openssl.cnf -extensions Server
이제 사용할 비밀 키와 인증서를 만들었다.
!! 참고 !!
CSR을 만들 때, Common Name을 localhost로 입력해야 한다. 만약, localhost로 하지않는다면 request 테스트할 때 아래와 같은 에러를 마주할 것이다.
curl: (60) SSL: certificate subject name 'KYJ' does not match target host name 'localhost'
2.2 HTTP 서버와 인증서 등록
HTTPS 접속 테스트를 위해, HTTPS 서버를 준비하자. 코드는 아래와 같다.
package main
import (
"fmt"
"log"
"net/http"
"net/http/httputil"
)
func handler(w http.ResponseWriter, r *http.Request) {
dump, err := httputil.DumpRequest(r, true)
if err != nil {
http.Error(w, fmt.Sprint(err), http.StatusInternalServerError)
return
}
fmt.Println(string(dump))
fmt.Fprintf(w, "<html><body>hello</body></html>\n")
}
func main() {
http.HandleFunc("/", handler)
log.Println("start http listening : 18443")
err := http.ListenAndServeTLS(":18443", "/openssl/server.crt", "/openssl/server.key", nil)
log.Println(err)
}http와 크게 다르지 않지만, listenAndServer부분이 TLS가 붙은 것을 볼 수 있다. 그리고 작성한 인증서와 비밀 키의 파일 이름을 인수로 받는다.
직접 request를 날려보자.
$ curl https://localhost:18443
curl: (60) SSL certificate problem: unable to get local issuer certificate
More details here: https://curl.se/docs/sslcerts.html
위와 같은 오류가 날 것이다. curl 커맨드가 인증서를 찾지 못했기 때문이다.
인증서를 포함해서 아래와 같이 request를 보내자.
curl --cacert ca.crt https://localhost:18443
성공적으로 response가 오는 모습을 볼 수 있다.
2.3 Go 언어를 이용한 클라이언트 구현
Go 언어를 사용해서 서버를 구현하는 코드는 매우 단순했다. 클라이언트를 구현하는 코드도 아래와 같이 단순하다.
package main
import (
"crypto/tls"
"crypto/x509"
"log"
"net/http"
"net/http/httputil"
"os"
)
func main() {
cert, err := os.ReadFile("../openssl/ca.crt")
if err != nil {
panic(err)
}
certPool := x509.NewCertPool()
certPool.AppendCertsFromPEM(cert)
tlsConfig := &tls.Config{
RootCAs: certPool,
InsecureSkipVerify: true, // 안정성 낮은 tls
}
// 클라이언트 작성
client := &http.Client {
Transport: &http.Transport{
TLSClientConfig: tlsConfig,
},
}
// 통신
resp, err := client.Get("https://localhost:18443")
if err != nil {
panic(err)
}
defer resp.Body.Close()
dump, err := httputil.DumpResponse(resp, true)
if err != nil {
panic(err)
}
log.Println(string(dump))
}
2.4 클라이언트 인증서
TLS의 기능 중에 클라이언트 인증서를 이용한 클라이언트 인증이 있다. 이 기능은 보통의 TLS와 반대로 서버가 클라이언트에 인증서를 요구한다. server측 코드를 아래와 같이 수정한다.
package main
import (
"crypto/tls"
"fmt"
"log"
"net/http"
"net/http/httputil"
)
func handler(w http.ResponseWriter, r *http.Request) {
dump, err := httputil.DumpRequest(r, true)
if err != nil {
http.Error(w, fmt.Sprint(err), http.StatusInternalServerError)
return
}
fmt.Println(string(dump))
fmt.Fprintf(w, "<html><body>hello</body></html>\n")
}
func main() {
server := &http.Server{
TLSConfig: &tls.Config{
ClientAuth: tls.RequireAndVerifyClientCert,
MinVersion: tls.VersionTLS12,
},
Addr: ":18443",
}
http.HandleFunc("/", handler)
log.Println("start http listening :18443")
err := server.ListenAndServeTLS("../openssl/server.crt", "../openssl/server.key")
log.Println(err)
}client 키와 인증서를 다시 아래 명령어를 통해 생성해주자.
# RSA 2048 비트 비밀 키 생성
$ openssl genrsa -out client.key 2048
# 인증서 서명 요청(CSR) 작성
$ openssl req -new -nodes -sha256 -key client.key -out client.csr -config openssl.cnf
# 인증서를 자신의 비밀 키로 서명해서 생성
$ openssl x509 -req -days 365 -in client.csr -sha256 -out client.crt -CA ca.crt -CAkey ca.key -CAcreateserial -extfile ./openssl.cnf -extensions Client
client 측 코드도 아래와 같이 변경해보자.
package main
import (
"crypto/tls"
"log"
"net/http"
"net/http/httputil"
)
func main() {
cert, err := tls.LoadX509KeyPair("../openssl/client.crt", "../openssl/client.key")
if err != nil {
panic(err)
}
client := &http.Client{
Transport: &http.Transport{
TLSClientConfig: &tls.Config{
Certificates: []tls.Certificate{cert},
},
},
}
// 아래는 앞의 코드와 같다.
}
3.0 프로토콜 업그레이드
프로토콜 업그레이드는 통신 도중에 HTTP 이외의 통신을 하는 방법이었다. go의 표준 net/http 패키지는 많은 일을 해주지만, 업그레이드 후에는 HTTP의 문맥에서 벗어나 통신하므로 직접 소켓을 송수신하게 된다. 원래는 HTTP처럼 제대로 된 송수신 규약을 만들 필요가 있지만, 이 책에서는 예제로서 간단히 송수신만 하는 프로토콜을 구현한다.
3.1 서버 코드
서버 쪽도 특수한 통신을 할 필요가 있기때문에 핸들러를 작성하자. 서버쪽 코드에 아래와 같은 핸들러를 추가했다.
func handlerUpgrade(w http.ResponseWriter, r *http.Request) {
// 이 엔드포인트에서는 변경 외는 받아들이지 않는다.
if r.Header.Get("Connection") != "Upgrade" || r.Header.Get("Upgrade") != "MyProtocol" {
w.WriteHeader(400)
return
}
fmt.Println("Upgrade to MyProtocol")
// 소켓을 획득
hijacker := w.(http.Hijacker)
conn, readWriter, err := hijacker.Hijack()
if err != nil {
panic(err)
return
}
defer conn.Close()
// 포로토콜이 바뀐다는 응답을 보낸다.
response := http.Response{
StatusCode: 101,
Header: make(http.Header),
}
response.Header.Set("Upgrade", "MyProtocol")
response.Header.Set("Connection", "Upgrade")
response.Write(conn)
// 오리지널 통신 시작
for i := 1; i <= 10; i++ {
fmt.Fprintf(readWriter, "%d\n", i)
fmt.Println("->", i)
readWriter.Flush() // Trigger "chunked" encoding and send a chunk ...
recv, err := readWriter.ReadByte()
if err == io.EOF {
break
}
fmt.Printf("<- %s", string(recv))
time.Sleep(500 * time.Millisecond)
}
}이 코드에서 핵심은 2곳이다. http.ResponseWriter를 http.Hijacker로 캐스팅하는 부분이다. 하이재킹하면 http.ResponseWriter는 아무런 전송 메시지를 보내지 않게 된다. header와 statuscode를 보내지 않는 대신 소켈을 직접 조작할 수 있게 된다. 소켓을 닫는 것은 프로그래머의 책임이다.
또 한 곳은 http.Response를 만들어 response.Write() 소켓에 응답을 수동으로 써넣는 부분이다. 소켓을 직접 읽고 쓸 경우 conn.Write()를 사용해 HTTP 응답을 직접 써넣을 수도 있지만, 이 헬퍼 메서드를 사용하면 수동으로 출력 포맷을 HTTP로 정돈할 필요가 없어진다. 연결을 유지한 채로 HTTP의 응답을 반활할 수 있다.
하이재킹 시 응답의 두 번쨰는 낮은 수준의 소켓을 감싼 bufio.ReadWriter이다. bufio.ReadWriter는 io.Reader에 데이터 읽기를 편리하게 하는 bufio.Reader와 쓰기를 편리하게 하는 bufio.Writer 기능을 추가한 입출력용 인터페이스이다.
Tip!
하이재킹(Hijacking)은 컴퓨터 보안 용어 중 하나로, 일반적으로 컴퓨터 네트워크나 시스템을 불법적으로 점령하거나 통제하는 행위를 가리킵니다. 이는 보안을 위협하고, 사용자의 개인정보를 탈취하거나 시스템을 악용하여 다른 공격에 이용될 수 있습니다. 종종 악성 소프트웨어나 악성 코드를 사용하여 시스템에 침입하거나, 네트워크 상에서 데이터를 가로채는 등의 방법으로 이루어집니다. 이는 비인가된 접근으로 인해 사용자나 시스템 소유자의 권한을 빼앗거나 피해를 입히는 행위로 볼 수 있습니다.
테스트를 해보고싶다면 main 함수를 아래와 같이 작성해주면 된다.
func main() {
http.HandleFunc("/upgrade", handlerUpgrade)
log.Println("start http listening :18888")
err := http.ListenAndServe(":18888", nil)
if err != nil {
log.Println(err)
}
}
3.2 클라이언트 코드
클라이언트 쪽 코드도 소켓을 직접 다룬다. 서버와 같은 하이재킹 구조가 없으므로, 통신을 시작할 때부터 소켓을 다룰 필요가 있다. 코드는 아래와 같다.
package main
import (
"bufio"
"fmt"
"io"
"log"
"net"
"net/http"
"time"
)
func main() {
// TCP 소켓 열기
dialer := &net.Dialer{
Timeout: 30*time.Second,
KeepAlive: 30*time.Second,
}
conn, err := dialer.Dial("tcp", "localhost:18888")
if err != nil {
panic(err)
}
defer conn.Close()
reader := bufio.NewReader(conn)
// 요청을 작성해 소켓에 직접 써넣기
request, _ := http.NewRequest("GET", "http://localhost:18888/upgrade", nil)
request.Header.Set("Connection", "Upgrade")
request.Header.Set("Upgrade", "MyProtocol")
err = request.Write(conn)
if err != nil {
panic(err)
}
// 소켓에서 직접 데이터를 읽어와 응답 분석
resp, err := http.ReadResponse(reader, request)
if err != nil {
panic(err)
}
log.Println("Status:", resp.Status)
log.Println("Headers:", resp.Header)
// 오리지널 통신 시작
counter := 10
for {
data, err := reader.ReadByte()
if err == io.EOF {
break
}
fmt.Println("<-", string(data))
fmt.Fprintf(conn, "%d\n", counter)
fmt.Println("->", counter)
counter--
}
}net.Dialer 구조체를 사용해 TCP 소켓을 연다. request.Writer로 소켓에 직접 요청을 적는다. 요청에는 서버에서 기대하는 헤더값을 추가한다. 여기서도 마찬가지로 bufio.Reader의 ReadBytes() 메서드를 이용한다.
4.0 청크
Go 에서 청크는 net/http의 각 기능에 처음부터 들어있다. API를 사용할 경우 완전히 통신 패키지 내부에 은폐돼 있으므로, 단순히 송수신하는 것 뿐이라면 통신이 청크 방식으로 이루어지는지 의식할 필요는 없다.
http.Post로 2048바이트 이상의 파일을 전송할 때, Request.ContentLength를 설정하지 않고 보낼 경우 자동으로 청크 형식으로 업로드 된다. ioutil.ReadAll()을 호출하면 다 읽을 때까지 블록한다. 1초씩 10회로 나누어 데이터를 수신하는 경우는 10초 후에 모아서 통신 결과가 돌아온다. 청크 송수신을 Go 언어로 구현하는 방법을 배워보자.
- 서버에서 청크 형식으로 송신하기
- 클라이언트에서 순차적으로 수신하기 (간단판)
- 클라이언트에서 순차적으로 수신하기 (완전판)
- 클라이언트에서 송신하기
4.1 서버에서 송신하기
서버에서 청크 형식으로 전송하는 것은 간단하다. http.ResponseWriter를 http.Flusher 인터페이스로 캐스팅하면, 숨겨진 Flush() 메서드를 사용할 수 있게 된다.
func handlerChunked(w http.ResponseWriter, r *http.Request) {
flusher, ok := w.(http.Flusher)
if !ok {
panic("expected http.ResponseWriter to be an http.Flusher")
}
for i := 1; i <= 10; i++ {
fmt.Fprintf(w, "Chunk #%d\n", i)
flusher.Flush()
time.Sleep(500*time.Millisecond)
}
flusher.Flush()
}
이 코드는 0.5초마다 텍스트를 클라이언트에 반환한다. 이전 코드에선 모두 출력한 후에 클라이언트에 메시지를 보냈지만, 해당 코드에선 출력할 때마다 Flush()를 호출함으로써 클라이언트는 루프를 돌 때마다 결과를 받게 된다.
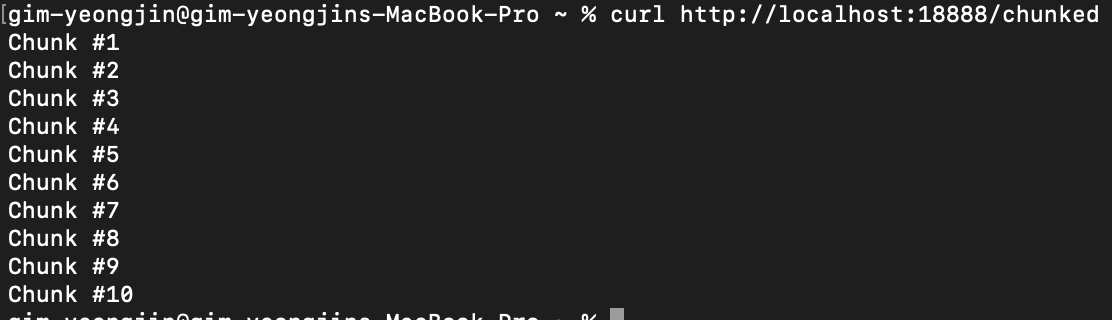
루프 안의 Flush()를 추석처리하고 돌려보면, 1번씩 출력되는 것이 아닌 한번에 출력이 된다.
4.2 클라이언트에서 순차적으로 수신하기 (간단판)
package main
import (
"bufio"
"bytes"
"io"
"log"
"net/http"
)
func main() {
resp, err := http.Get("http://localhost:18888/chunked")
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
reader := bufio.NewReader(resp.Body)
for {
line, err := reader.ReadBytes('\n')
if err == io.EOF {
break
}
log.Println(string(bytes.TrimSpace(line)))
}
}bufio.Reader의 ReadBytes()로 구분 문자까지의 내용을 읽고 있다. 서버에서 1초에 한줄씩 전송되고 있다면, ReadBytesd() 메서드는 응답이 올 때까지 블록된다.
이런 구조만으로 서버 쪽에서 임의의 시점에서 응답을 할 수 있게 된다. 이 방법은 사용자가 올바른 형식으로 보내는 것을 전제로 하는 방법이다. 끝에 구분 문자 이외 다른 것이 있으면, 거기서 처리가 차단되어 버린다.
4.3 클라이언트에서 순차적으로 수신하기 (완전판)
업그레이드 구현에선 TCP 소켓을 직접 다룸으로써 임의의 프로토콜에 대응할 수 있었다. 청크도 같은 방법으로 직접 다룰 수 있다.
청크의 기능은 단순하다.
- 16진수의 청크 길이가 전송된다.
- 지정된 크기의 데이터가 전송된다.
- 길이 0이 전송되면, 서버에서의 응답이 끝난 것을 알 수 있다.
저수준 소켓으로 청크를 직접 읽어오게 한 것이 아래 코드이다.
package main
import (
"bufio"
"io"
"log"
"net"
"net/http"
"strconv"
"time"
)
func main() {
// TCP 소켓 열기
dialer := &net.Dialer{
Timeout: 30*time.Second,
KeepAlive: 30*time.Second,
}
conn, err := dialer.Dial("tcp", "localhost:18888")
if err != nil {
panic(err)
}
// 요청 보내기
request, err := http.NewRequest("GET", "http://localhost:18888/chunked", nil)
err = request.Write(conn)
if err != nil {
panic(err)
}
// 읽기
reader := bufio.NewReader(conn)
// 헤더 읽기
resp, err := http.ReadResponse(reader, request)
if err != nil {
panic(err)
}
if resp.TransferEncoding[0] != "chunked" {
panic("wrong transfer encoding")
}
for {
// 크기를 구하기
sizeStr, err := reader.ReadBytes('\n')
if err == io.EOF {
break
}
// 16진수의 크기를 해석. 크기가 0이면 닫는다.
size, err := strconv.ParseInt(string(sizeStr[:len(sizeStr)-2]), 16, 64)
if size == 0 {
break
}
if err != nil {
panic(err)
}
// 크기만큼 버퍼를 확보하고 읽어오기
line := make([]byte, int(size))
reader.Read(line)
reader.Discard(2)
log.Println(" ", string(line))
}
}
5.0 원격 프로시저 호출
Go 언어는 net/rpc 패키지에서 RPC를 실현하는 프레임워크를 제공한다. 오브젝트를 생성해 등록하면, 외부에서 액세스할 수 있게 된다.
net/rpc에서 공개되는 메서드는 아래 조건을 충족시켜야 한다.
- 메서드가 속한 구조체의 형이 공개되어 있다.
- 메서드가 공개되어 있다. (대문자로 시작하는 이름을 가진다.)
- 메서드는 두 개 인수를 가지며, 양쪽 다 공개되어 있거나 내장형이다.
- 메서드의 두 번째 인수는 포인터이다.
- 메서드는 error 형의 반환값을 가진다.
아래 코드는 각각 JSON-RPC 서버와 클라이언트가 된다.
package main
import (
"log"
"net"
"net/http"
"net/rpc"
"net/rpc/jsonrpc"
)
// 메서드가 속한 구조체
type Calculator int
// RPC로 외부에서 호출되는 메서드
func (c *Calculator) Multiply(args Args, result *int) error {
log.Printf("Multiply called: %d, %d\n", args.A, args.B)
*result = args.A*args.B
return nil
}
// 외부에서 호출될 때의 인수
type Args struct {
A, B int
}
func main() {
calculator := new(Calculator)
server := rpc.NewServer()
server.Register(calculator)
http.Handle(rpc.DefaultRPCPath, server)
log.Println("start http listening :18888")
listener, err := net.Listen("tcp", ":18888")
if err != nil {
panic(err)
}
for {
conn, err := listener.Accept()
if err != nil {
panic(err)
}
go server.ServeCodec(jsonrpc.NewServerCodec(conn))
}
}server 코드로 net.rpc.Server를 작성한다. 계산 처리를 할 구조체를 추가하고 HTTP 핸들러로서 등록한다. 그 후에는 클라이언트에서 접속이 있을 때마다 JSON-RPC의 코덱을 만들어 서버에 등록한다.
package main
import (
"log"
"net/rpc/jsonrpc"
)
type Args struct {
A, B int
}
func main() {
client, err := jsonrpc.Dial("tcp", "localhost:18888")
if err != nil {
panic(err)
}
var result int
args := &Args{4, 5}
err = client.Call("Calculator.Multiply", args, &result)
if err != nil {
panic(err)
}
log.Printf("4 x 5 = %d\n", result)
}client 코드는 더 간단하다. jsonrpc.Dial 함수를 호출하면 코덱이 설정된 클라이언트가 반환되므로, 반환된 클라이언트의 Call 메서드로 서버의 메서드를 호출할 수 있다. RPC 관련 기능은 표준 API로 제공되지만, 품질이 높다고는 할 수 없다. 대기하는 경로와 코덱을 동시에 간단히 지정할 수 있는 API가 없고, 어느 한 쪽을 기본으로 사용하는 방법만 제공된다.
Reference
- 리얼월드 HTTP
- https://chat.openai.com/
'개발 서적 > 리얼월드 HTTP' 카테고리의 다른 글
| HTTP/2의 시맨틱스: 새로운 활용 사례 (0) | 2024.04.09 |
|---|---|
| HTTP/2의 신택스 : 프로토콜 재정의 (0) | 2024.03.29 |
| HTTP/1.1의 시맨틱스: 확장되는 HTTP의 용도 (0) | 2024.03.03 |
| HTTP/1.1 고속화와 안정성을 추구한 확장 (0) | 2024.02.14 |
| 검색 엔진용 콘텐츠 접근 제어 (0) | 2024.02.14 |