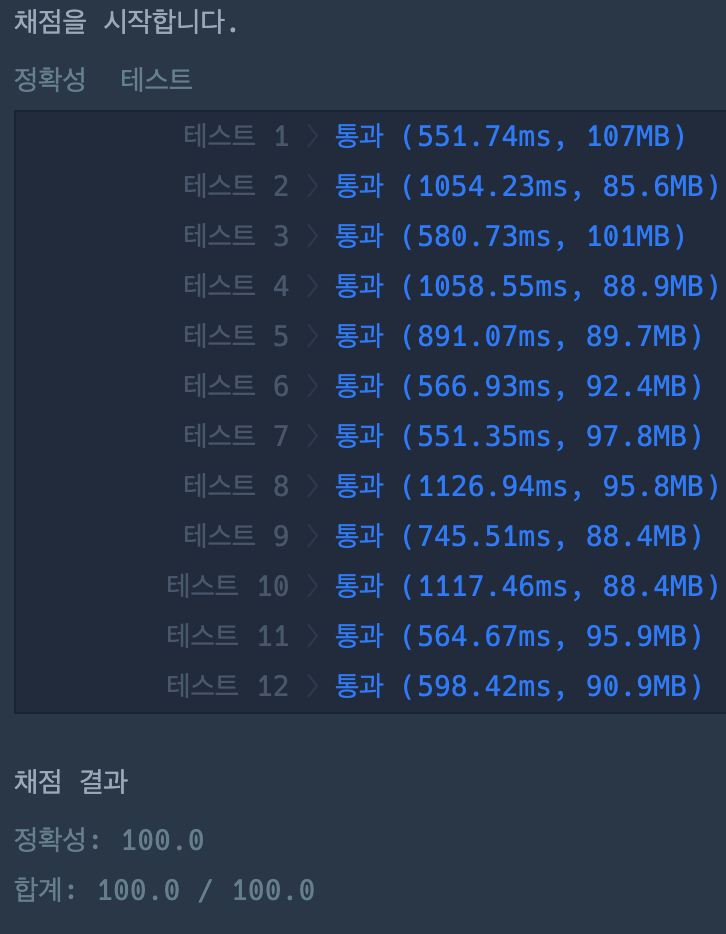
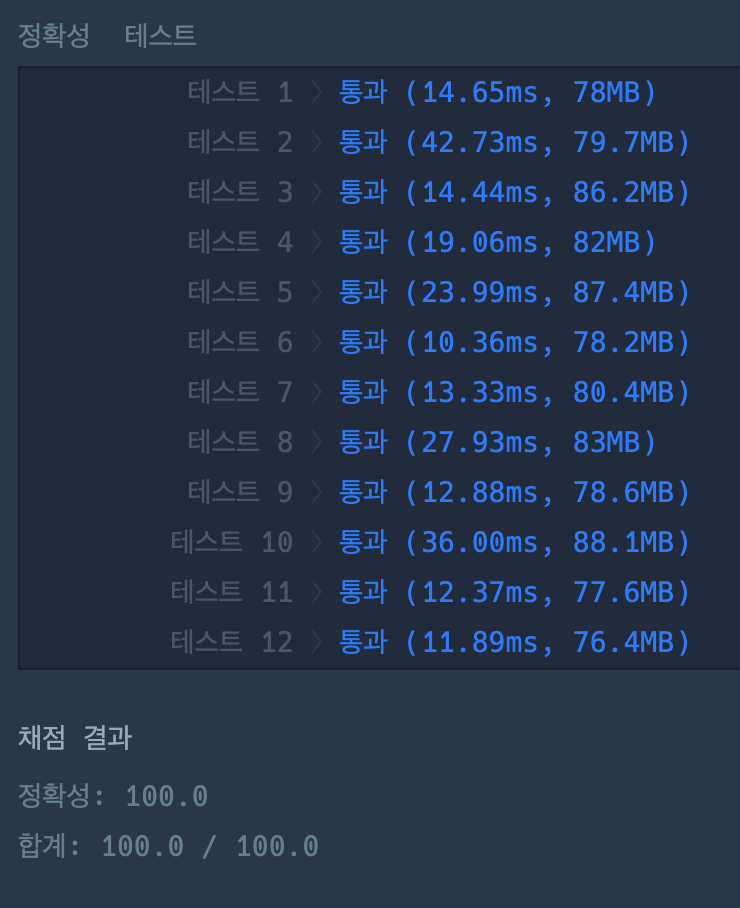
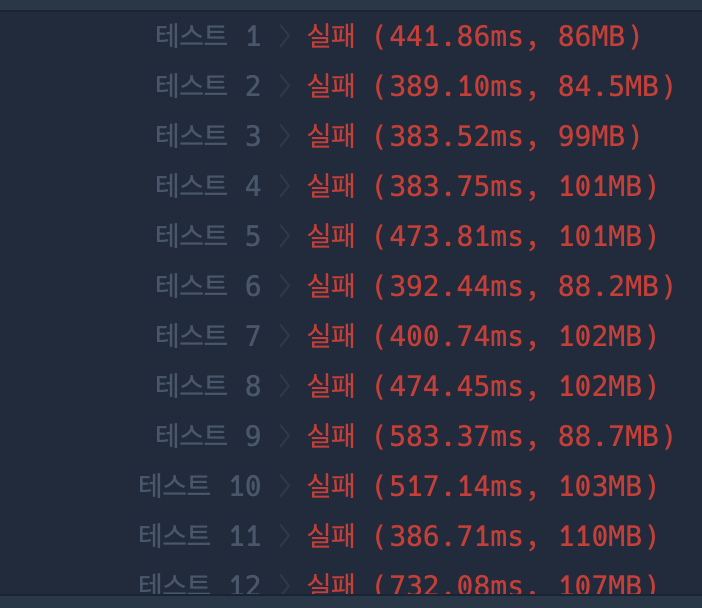
1. Java와 비교했을 때, Node.js는 작고 느린 Single Thread 서버이다. Java는 각 HTTP 요청을 별도의 Thread에서 처리하지만, Node.js는 모든 요청을 하나의 Thread로 처리. -> 즉, Java Spring은 여러 HTTP 요청을 동시에 처리할 수 있지만 Node.js의 경우 한번에 1개의 요청만 처리할 수 있습니다. 그렇기때문에 강력한 서버에 Node.js를 설치하더라도, 100%의 성능을 활용할 수가 없습니다.
2. Node.js가 사용하는 언어인 Javascript는 신기한(?) 언어다. Java, script 두개가 합쳐졌지만 자바도 아니고, 단순히 스크립트 언어도 아니라고 합니다. 다른 고급 언어와는 다르게, 자바스크립트는 단순히 웹 브라우저 화면을 컨트롤 하는 스크립트 용도로 만들어진 언어입니다.
그렇기에 발전한 지금의 자바스크립트에는 간단해 보이는 코드 사이사이에 여러 혼란스러운 변화의 흔적들이 남아있습니다. (`this` keyword의 난해함, 혼란스러운 scope 개념 등..)
Javascript는 좋은 부분이 많은 언어이지만, 위험하고 나쁜 부분은 더 많은 언어로 `잘` 알아야 할 필요가 있습니다.
장점
1. Node.js는 (작고 가벼운) Single Thread 서버이다. 말이 아 다르고 어 다르다는 말처럼, Node.js 서버는 Java와 비교했을 때, 작고 느린것은 맞지만 작고 가볍다고 볼 수도 있습니다.
작고 가벼운 Node.js 서버는 대규모 트래픽을 받아주기에는 크게 유용하게 생각되지는 않았습니다.
하지만, Monolithic Architecture를 대체하여 관심받는 MSA(Micro Service Architecture) 구조와 서버 배포와 관리를 간단하고 빠르게 해줄 수 있는 k8s(kubernetes)가 유행을 탄 후, 상황은 조금 달라졌습니다.
MSA는 거대한 서버를 서비스 기능 별로 나눌 뿐만 아니라, 트래픽을 나눕니다. 예를 들어, 쇼핑몰 회사에서 2대로 모든 서비스 요청을 처리하고 있었다치면, MSA 구조에서는 이벤트 서버 2대, 상품 리스트/추천 서버 2대, 주문/배송 처리 서버 3대 등으로 나눠질 수 있습니다.
얼핏 보았을 때, 2대 vs 7대로 비효율적으로 보이는 MSA 구조는 트래픽이 많이 몰릴 때 빛을 발합니다. 만약, 어떤 시간 한정 이벤트가 발생해서 이벤트 시간에만 사람이 100배로 증가한다면, 이벤트 서버만 증설해주면 트래픽을 문제없이 처리할 수 있습니다. 또한, 이런 증설은 트래픽을 감지한 k8s 시스템이 자동으로 진행해 줍니다. 뿐만아니라, Node.js의 서버 가동 시간은 1초 이내(java spring 서버 가동 시간은 10 ~ 20초 사이)로 갑자그러운 트래픽에 즉각적으로 대응하기에도 유리합니다.
Node.js는 작고 가벼운 장점이 있다고 했습니다. 이는 JVM위에서 구동되는 Java Spring은 Node.js에 비해 무겁다는 것을 의미합니다. 구체적인 예시를 들자면, 아무것도 하지 않는 Java Spring은 400MB 가량의 Memory를 사용하는데 반해, Node.js는 25MB 정도의 Memory만을 사용합니다. (참조 : 링크) 1대의 서버에서 약 375MB가 차이나는데, N대의 서버를 MSA 구조에서 사용한다면 N*375MB의 Memory가 차이가 날 것입니다.
최근 MSA와 k8s가 유행하며 서버 수 자체도 늘고, 서버 수가 트래픽에 맞춰 유동적으로 바뀌는 상황이 많아졌으며, 크고 강력한 한 대의 서버보다는 빠르고 가벼운 서버가 여러대 있는 쪽이 유리한 상황이 많아졌습니다. 이러한 상황에서 빠른 서버 가동 시간과 적은 Memory 사용량 등 Node.js의 가벼움은 빛을 발하고 있습니다.
처리 능력이 떨어지거나 하나의 thread만 사용해 응답성이 떨어지는 단점들은 서버를 여러대 두면 무마 가능하게 되었습니다. (Single Thread 서버 여러 대 == Multi Thread 서버 1대)
또한, Single Thread 서버의 장점이 있습니다. Single Thread 서버에는 오로지 하나의 thread만 존재하기 때문에, concurrency 지옥에서 고통 받을 필요가 없습니다.
2. Javascript 언어는 나아지고(!) 있다. Javascript는 호불호가 갈리는 언어라고 합니다. Javasciprt의 가장 큰 단점 중 한 가지는 타입이 없기에, 타입을 강제할 방법이 없었다는 것 입니다.
예를 들어, javascript로 아래와 같이 함수를 짰다면
function plus(number1, number2)
{
return number1 + number2;
}
우리는 함수를 사용하는 사람한테 number1, number2를 숫자로 쓰라고 강제할 수 없습니다. (어..? 이걸 하나하나 기억해야하나..)
함수 사용자가 아래와 같은 악랄한(!) 짓을 해도 딱히 막을 방법은 없습니다.
var result = plus('1', '2') // 3...! 다행이 이건 의도대로 작동합니다.
var result2 = plus('2', 'number') // '2number'? 우리가 원했던 결과는 아니네요
var result3 = plus(1, '2') // 12, 여기부터 심각하게 잘못된 결과가 나오기 시작합니다.
우리가 할 수 있는 최선은 주석을 길게 달아 사용자에게 제발 이 함수를 정확히 써달라고 아래와 같이 명시(!)하는 것 뿐입니다.
/**
* @param {number} number1- 더하는 첫번째 수, 제발 숫자만 넣어주세요 ㅜㅜ
* @param {number} number2- 더하는 두번째 수, 꼭 무조건 숫자만 ㅠㅠ;
*
* WARNING!!!! 숫자가 아닌 param을 넣으면 오작동함!!!!
*/
function plus(number1, number2) {
// ...
}
하지만, 이러한 주석 속의 울부짖음을 무시할 사람은 너무나 많습니다. 소규모 프로젝트에서는 큰 문제가 되지 않았지만, javascript에도 많은 대규모 프로젝트들이 생기며, 이 문제는 심해져 갔습니다. 다행히, 지금은 Typescript가 나왔습니다.
Typescript는 아주 기발한 방법으로 (솔직히 말하면 조금 꼼수를 써서) Javascript를 Type이 존재하는 언어로 재탄생 시켰습니다.
아무튼, Typescript의 탄생으로 인해 Javascript도 type이 있는 interface를 개발자들에게 제공해 줄 수 있게 되었고, Javascript는 대규모 개발에는 어울리지 않는다는 오명도 조금은 벗을 수 있게 되었습니다.
Nest.js의 출시 역시 놓칠 수 없는 포인트입니다.
Java Spring이라는 Framework가 제공하는 DI, IoC 기반의 개발은 Java를 포기하기 힘들게 만드는 Spring의 큰 장점입니다. 하지만, 지금은 Nest.js의 출시로 인해, Javascript에서도 마치 Java Spring을 쓰는 것처럼 Annotation을 통해 편리하게 DI, IoC 기반의 개발을 할 수 있습니다.
그리고 Nest.js는 Typeorm이라는 ORM 프레임워크 역시 적극적으로 지원하고 있기에, 더더욱 Java Spring + JPA 과 같은 조합을 쓰는 느낌으로 Javascript(Nest.Js + Typeorm) 개발을 할 수 있습니다.
Nest.js에 대해 조금 더 자세히 알고 싶으시다면 링크를 통해 글을 참조해보셔도 좋을 것 같다고 합니다.
또한, Javascript 진영에도 Jest나 Mocha 같은 좋은 테스트툴이 나왔기에 DI, IoC 구조가 제공하는 장점 중 하나인 `유닛테스트의 편리함` 역시 잘 활용할 수 있게 되었습니다.
결론은, 서버 개발 언어로서의 javascript는 발전하고 있다는 것 입니다. 부족한 부분은 채워지고 있고(Typescript, Next.js) 개발 툴 역시 보강되고 있습니다. (Typeorm, Jest, Mocha)
위에서도 말했지만, `Javascript는 좋은 부분이 많은 언어이지만, 위험하고 나쁜 부분은 더 많습니다.` 그렇지만 좋은 부분도 천천히, 하지만 확실하게 많아지고 있습니다.
네이버 파이낸셜의 페이플랫폼 직속 팀에서는 미래(PHP가 이끌던 백엔드 개발 트렌드를 Java Spring이 가져갔던 것처럼, 언젠가는 Node.js 역시 개발 트렌드를 주도)에 대비하여, 적극적으로 Node.js를 도입하고 노하우를 쌓아가고 있다고 합니다.
네이버 쇼핑 구매 목록 API를 제공하는 타임라인 서버
혜택 광고 API를 제공하는 리워드 서버
카드 정보 API를 제공하는 간편 입력 서버
마이데이터 API를 제공하는 마이데이터 서버
... 외 다양한 서버들을 Node.js(+ MSA, k8s)로 개발하고 운영하고 있다고 합니다. 또한, 대규모의 CPU 연산이 필요한 신규 DB 구축을 위한 마이그레이션 작업 역시 MSA 구조의 Node.js 서버로 처리해서, Node.js 서버로도 대규모 CPU 연산 작업이 가능하다는 것을 검증했고, 노하우를 쌓아가고 있다고 합니다.
내용들을 정리하며, Node.js에 대해 궁금해졌고 공부해보면 좋을 것 같다는 생각이 들었습니다. Java Spring을 경험해본 입장에서 비교해보며, 어떤 차이가 있는지 토이프로젝트를 진행해봐야겠습니다.
수평적 규모 확장성을 달성하기 위해서는 요청 또는 데이터를 서버에 균등하게 나누는 것이 중요하다. 안정 해시는 이 목표를 달성하기 위해 보편적으로 사용하는 기술이다. 하지만, 우선 이 해시 기술이 풀려고하는 문제부터 좀 더 자세하게 살펴보자.
해시 키 재배치(rehash) 문제
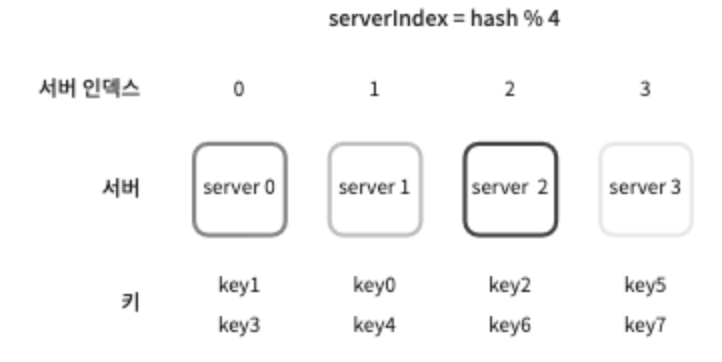
N개의 캐시 서버가 있다고 하자. 이 서버들에 부하를 균등하게 나누는 보편적 방법은 아래처럼 해시 함수를 사용하는 것이다. 이전에 봤던 기본적인 샤딩 방식과 동일하다.
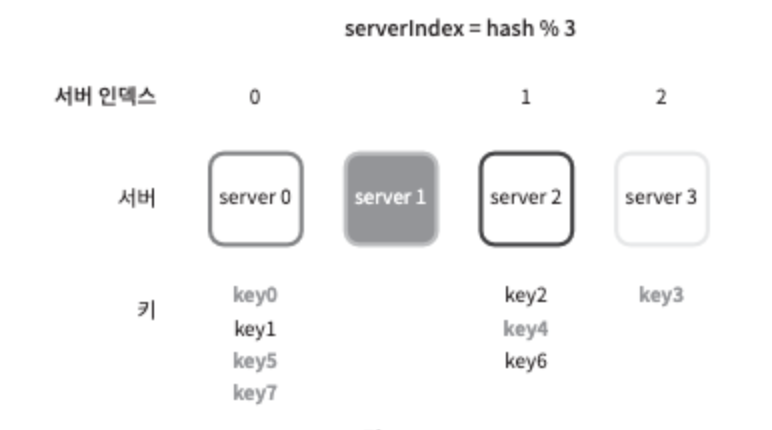
serverIndex = hash(key)%N (N은 서버의 수)
키
해시
서버 인덱스
key0
18358617
1
key1
26143584
0
key2
181311146
2
key3
35863496
0
key4
34085809
1
key5
27581703
3
key6
38164978
2
key7
22530351
3
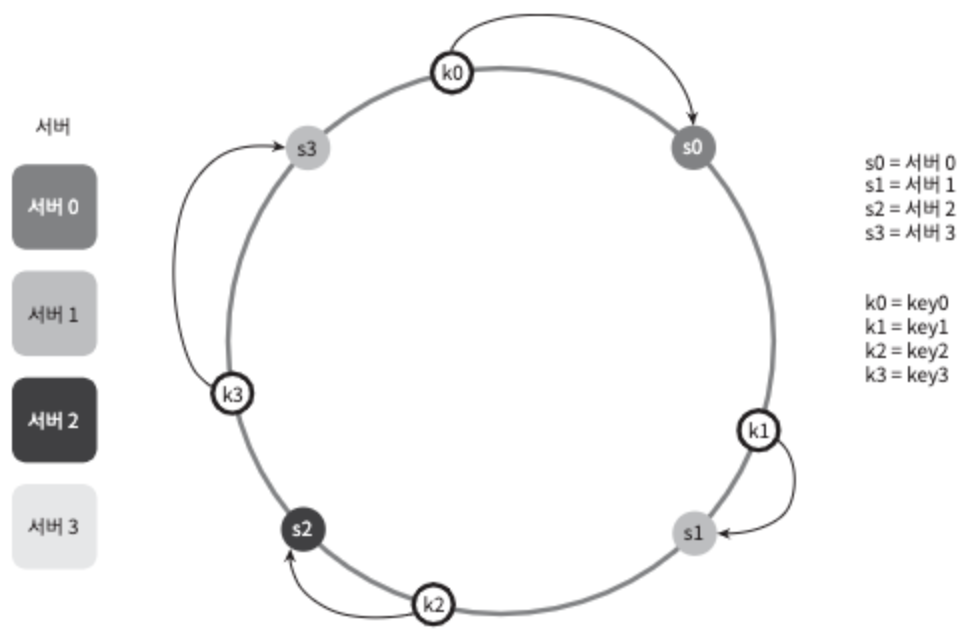
위는 총 4대의 서버를 사용할 때의 예시다.
그림 5-1
그림 5-1은 표의 key가 어떻게 분산되는지 보여준다. 해당 방법은 Server pool의 크기가 고정되어 있을 때, 그리고 데이터 분포가 균등할 때는 잘 동작한다. 하지만 서버가 추가되거나 기존 서버가 삭제되면 문제가 생긴다. 예를들어, server1이 장애가 발생하여 동작할 수 없을 때, server pool의 크기는 3으로 변한다. 키에 대한 해시 값은 변하지 않지만 나머지 연산을 적용하여 계산한 서버 인덱스 값은 달라질 것이다. 따라서 그림 5-2와 같은 결과를 얻는다.
그림 5-2
장애가 발생한 1번 서버에 보관되어 있는 키 뿐만 아닌 대부분의 키가 재분배되었다. 1번 서버가 죽으면 대부분 캐시 클라이언트가 데이터가 없는 엉뚱한 서버에 접소갛게 된다는 뜻이다. 그 결과로 대규모 캐시미스가 발생하게 될 것이다. 안정 해시는 이 문제를 효과적으로 해결하는 기술이다.
안정 해시
테이블 크기가 조정될 때 평균적으로 오직 k/n개의 키만 재배치하는 해시 기술이다. k는 키의 개수, n은 슬롯(slot)의 개수다.
해시 공간과 해시 링
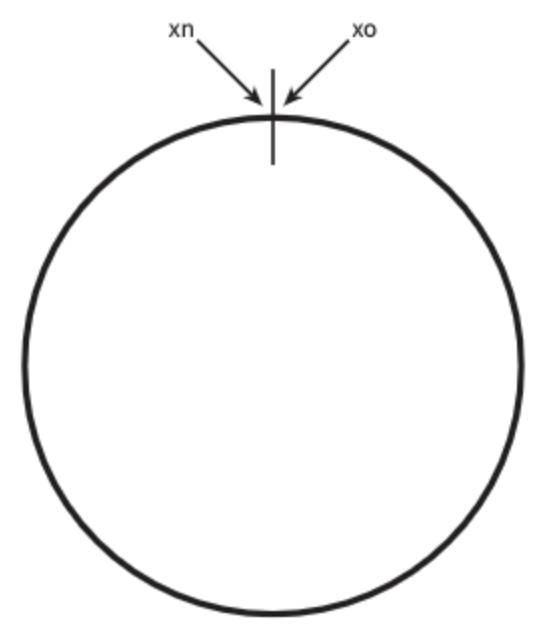
해시 함수 f로는 SHA-1을 사용한다고 하고, 그 함수의 출력 값 범위는 x0, ...., xn과 같다고 가정하자. SHA-1의 해시 공간(hash space) 범위는 0부터 2^160-1 까지라고 한다. 따라서 xn은 2^160-1이다.
그림 5-3그림 5-4
그림 5-3인 해시 공간을 양쪽으로 구부려 접으면 그림 5-4와 같은 해시 링이 만들어진다.
해시 서버
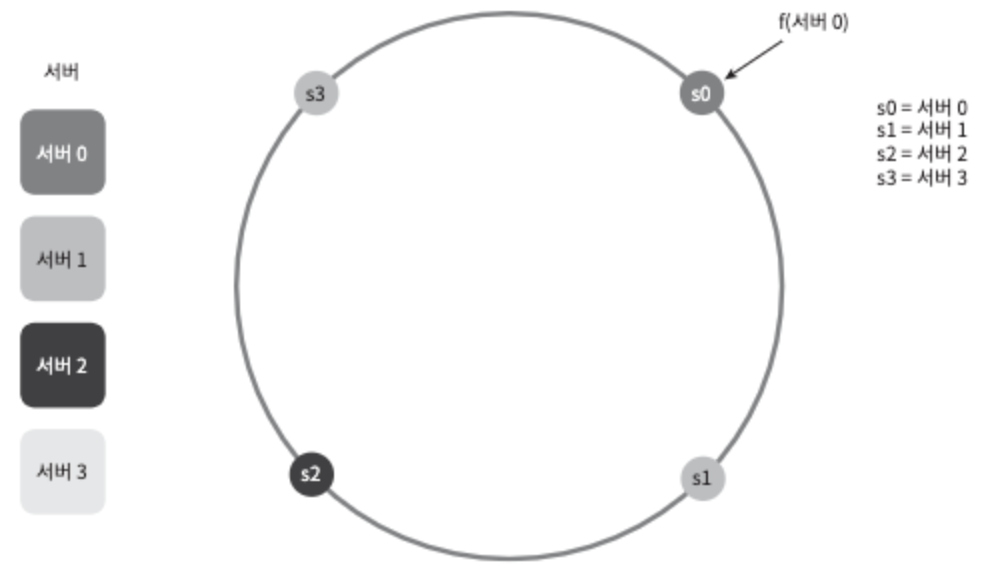
해시 함수 f를 사용하면 서버 IP나 이름을 링 위의 어떤 위치에 대응시킬 수 있다.
그림 5-5
그림 5-5는 4개의 서버를 해시 링 위에 배치한 결과다.
해시 키
여기 사용된 해시 함수는 "해시 키 재배치 문제"에 언급된 함수와는 다르며, 나머지 연산을 사용하지 않고 있음에 유의하자.
그림 5-6
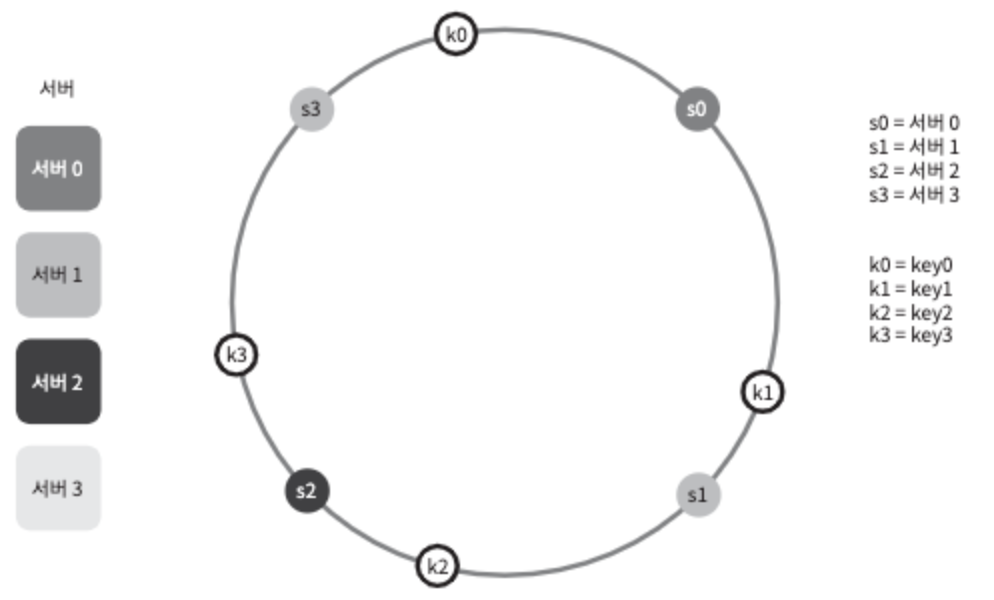
그림 5-6 같이, key 또한 해시 링의 어느 지점에 배치할 수 있다.
서버 조회
어떤 키가 저장되는 서버는, 해당 키의 위치로부터 시계 방향으로 링을 탐색해 나가면서 만나는 첫 번째 서버다.
그림 5-7
그림 5-7이 해당 과정을 보여준다.
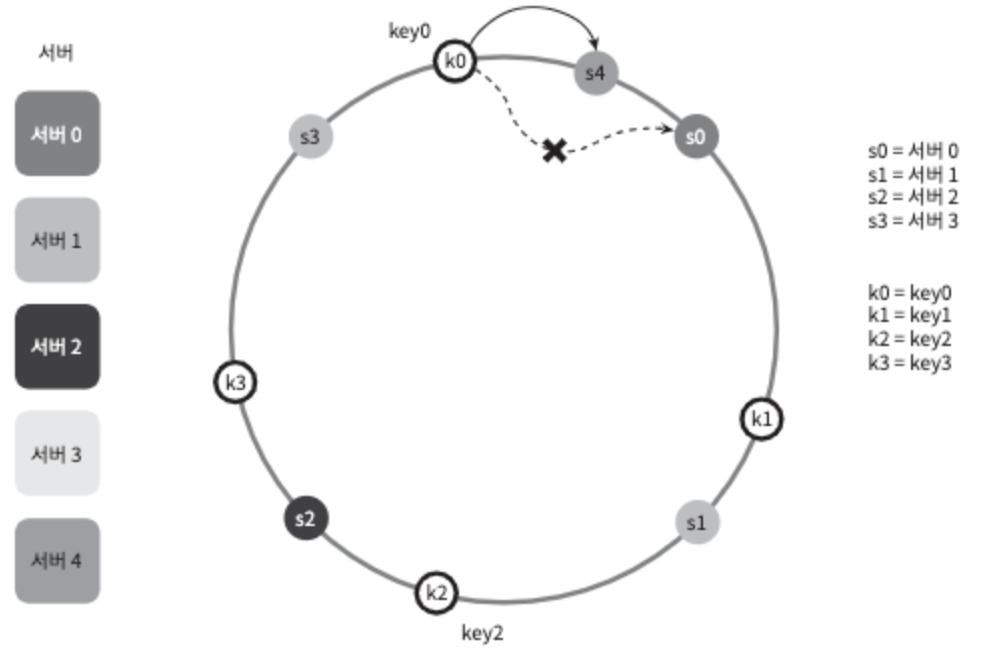
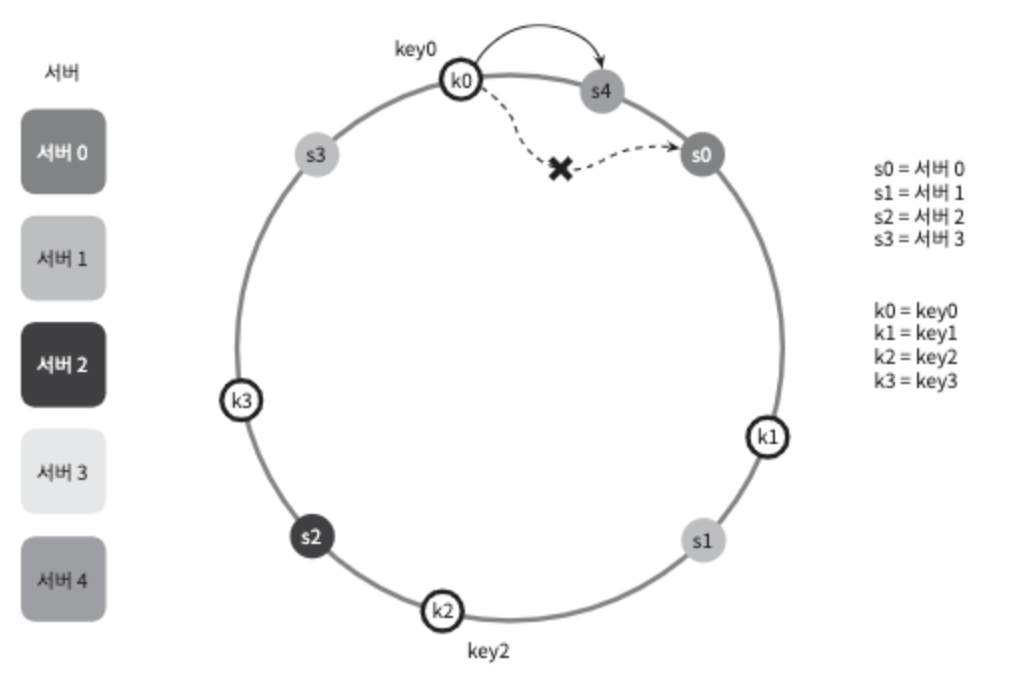
서버 추가
서버를 추가하더라도 키 가운데 일부만 재배치하면 된다.
그림 5-8
그림 5-8을 보면 새로운 서버4가 추가된 뒤에 key0만 재배치됨을 알 수 있다.
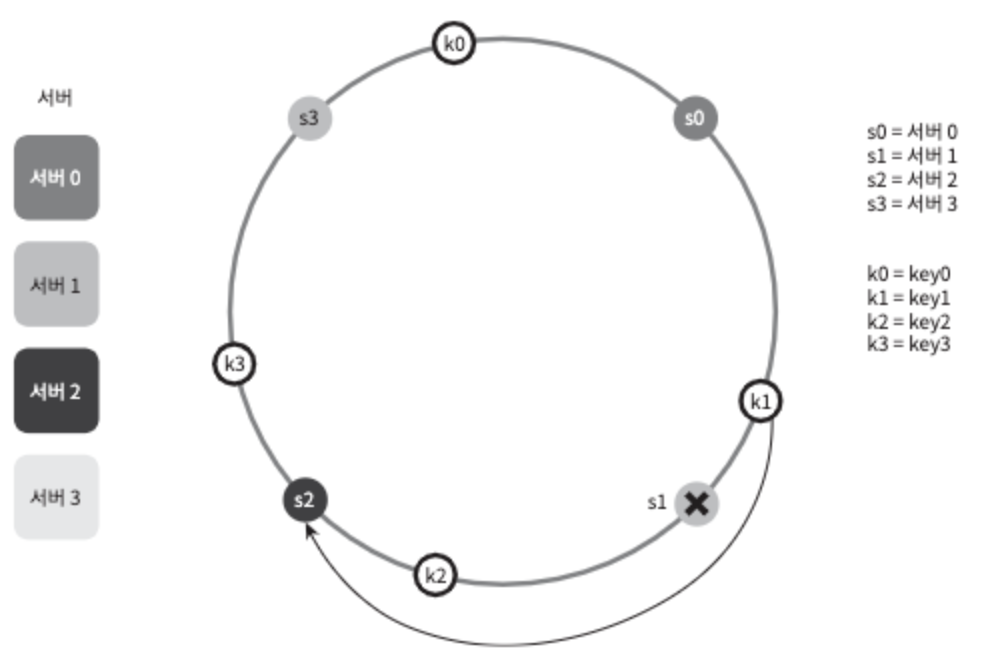
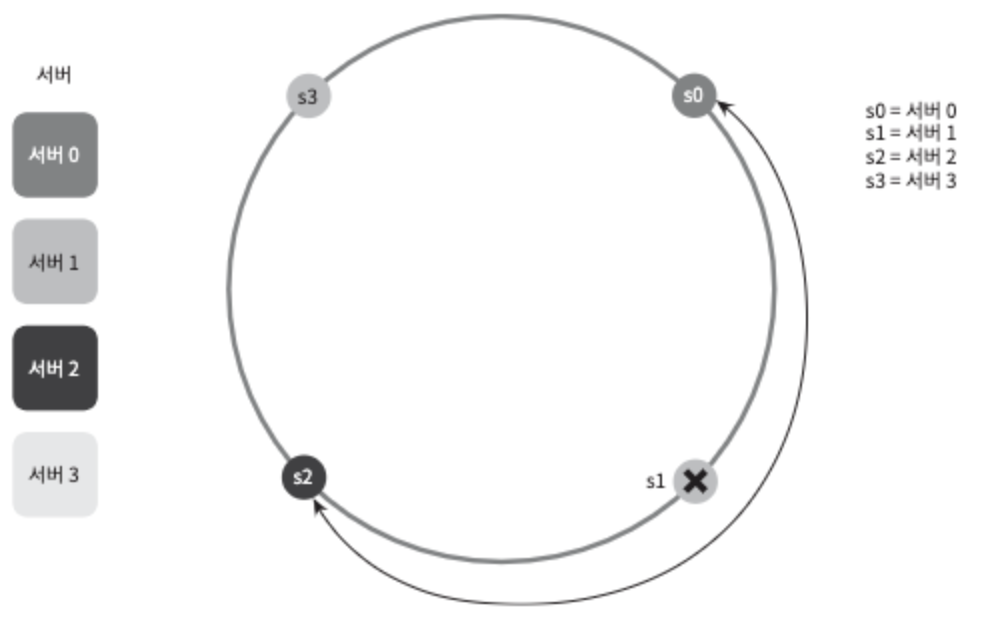
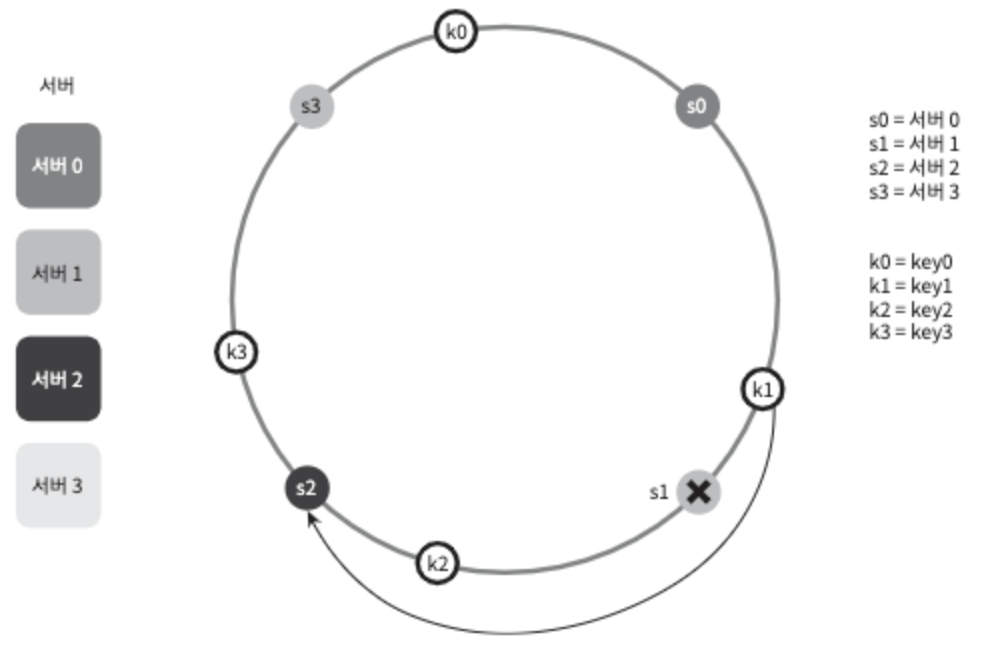
서버 제거
하나의 서버가 제거되면 키 가운데 일부만 재배치된다.
그림 5-9
그림 5-9를 보면 서버1이 삭제되었을 때, key1만이 server2로 재배치됨을 알 수 있다.
기본 구현법의 두 가지 문제
안정 해시 알고리즘은 MIT에서 처음 제안되었다. 그 기본 절차는 아래와 같다.
서버와 키를 균등 분포(uniform distribution) 해시 함수를 사용해 해시 링에 재배치한다.
키의 위치에서 링을 시계 방향으로 탐색하다 만나는 최초의 서버가 키가 저장될 서버다.
하지만, 이 접근법에는 두 가지 문제가 있다. 서버가 추가되거나 삭제되는 상황을 감안하면 파티션(partition)의 크기를 균등하게 유지하는 게 불가능하다는 것이 첫 번째 문제다. 여기서 파티션은 인접한 서버 사이의 해시 공간이다. 어떤 서버는 굉장히 작은 해시 공간을 할당 받고, 어떤 서버는 굉장히 큰 해시 공간을 할당 받는 상황이 가능하다는 것이다.
그림 5-10
그림 5-10은 s1이 삭제되는 바람에 s2의 파티션이 다른 파티션 대비 거의 2배로 커지는 상황을 보여준다. 2번째 문제는 키의 균등 분포(uniform distribution)를 달성하기가 어렵다는 것이다.
그림 5-11
예를 들어, 서버가 그림 5-11같이 배치되어 있다고 해보자. 서버1과 서버3은 아무 데이터도 갖지 않는 반면, 대부분의 키는 서버2에 보관될 것이다.
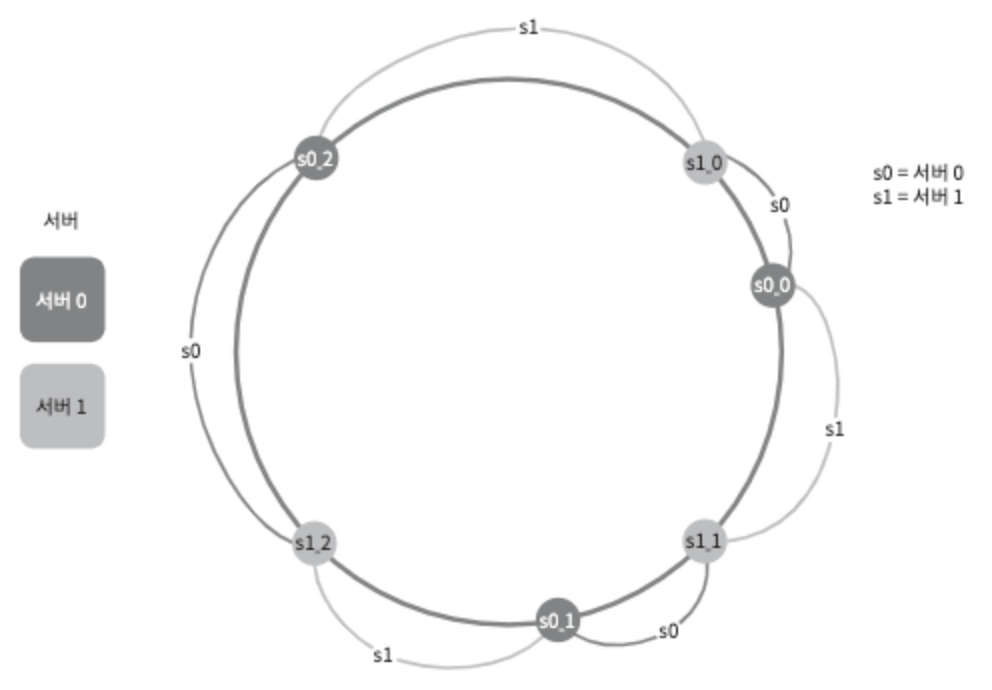
이 문제를 해결하기 위해 제안된 기법이 가상 노드(virtual node) 또는 복제(replica)라 불리는 기법이다.
가상 노드 or 복제
실제 노드 또는 서버를 가리키는 노드로서, 하나의 서버는 링 위에 여러 개의 가상 노드를 가질 수 있다.
그림 5-12
그림 5-12를 보면 서버0과 서버1은 3개의 가상 노드를 갖는다. 서버0을 링에 배치하기 위해 s0 하나만 쓰는 대신 s0_0, s0_1, s0_2인 가상 노드 3개를 사용했다. 따라서 서버는 1개가 아닌 여러 개 파티션을 관리해야 한다. 키의 위치로부터 시계방향으로 링을 탐색하다 만나는 최초의 가상 노드가 해당 키가 저장될 서버가 된다.
이렇게 가상 노드의 개수를 늘리면 키의 분포는 점점 더 균등해진다. 이유는 표준 편차(standard deviation)가 작아져서 데이터가 고르게 분포되기 때문이다. 링크에 따르면 100~200개의 가상 노드를 사용했을 경우 표준 편차 값은 평균의 5%~10%사이다. 가상 노드의 개수를 더 늘리면 표춘 편차의 값을 더 떨어진다. 타협적 결정(trade off)이 필요하다는 뜻이다. 그러니 시스템 요구사항에 맞도록 가상 노드 개수를 적절히 조정해야 할 것이다.
재배치할 키 결정
서버가 추가되거나 제거되면 데이터 일부는 재배치해야 한다.
그림 5-13
그림 5-13처럼 서버4가 추가되었다고 해보자. 이에 영향받는 범위는 s4부터 s3까지이다. 즉, s3부터 s4 사이에 있는 키들을 s4로 재배치해야 한다.
그림 5-14
그림 5-14같이 s1이 삭제되면 s1부터 s0 사이에 있는 키들이 s2로 재배치되어야 한다.
마치며
이번에는 안정 해시가 왜 필요하며 어떻게 동작하는지를 살펴봤다. 안정 해시의 이점은 아래와 같다.
서버가 추가되거나 삭제될 때 재배치되는 키의 수가 최소화된다.
데이터가 보다 균등하게 분포하게 되므로 수평적 규모 확장성을 달성하기 쉽다.
핫스팟(hotspot) 키 문제를 줄인다. 특정한 샤드(shard)에 대한 접근이 지나치게 빈번하면 서버 과부하 문제가 생길 수 있다.
안정 해시는 실제로 널리 쓰이는 기술이다. 그 중 유명한 것 몇가지를 예롤 들어보면 아래와 같다.
네트워크 시스템에서 처리율 제한 장치는 클라이언트 또는 서비스가 보내는 트래픽의 처리율(rate)을 제어하기 위한 장치다. HTTP를 예로 들면 이 장치는 특정 기간 내에 전송되는 클라이언트의 요청 횟수를 제한한다. API 요청 횟수가 제한 장치에 정의된 임계치(threshold)를 넘어서면 추가로 도달한 모든 호출은 처리가 중단(block)된다. 아래는 몇 가지 사례다.
사용자는 초당 2회 이상 새 글을 올릴 수 없다.
같은 IP 주소로는 하루에 10개 이상의 계정을 생성할 수 없다.
같은 디바이스로는 주당 5회 이상 리워드(reward)를 요청할 수 없다.
이렇게 클라이언트의 요청 횟수를 제한하는 이유는 아래와 같다.
DoS 공격에 의한 자원 고갈을 방지한다. 예시를 들면, 트위터는 3시간 동안 300개의 트윗만 올릴 수 있도록 제한한다. 구글 독스 API는 사용자당 분당 300회의 read 요청만 허용한다.
비용을 절감한다. 추가 요청에 대한 처리를 제한하면 서버를 많이 두지 않아도 되고, 우선순위가 높은 API에 더 많은 자원을 할당할 수 있다. 아울러 처리율 제한은 제3자(third-party) API에 사용료를 지불하고 있는 회사들에게 매우 중요하다.
서버 과부하를 막는다. bot에서 오는 트래픽이나 사용자의 잘못된 이용 패턴으로 유발된 트래픽을 걸러내는데 처리율 제한 장치를 활용할 수 있다.
1단계 문제 이해 및 설계 범위 확정
처리율 제한 장치에는 여러가지 알고리즘이 있다. 각각의 장단점이 있으니 면접시에 소통하며 적절한 알고리즘을 설정해야 한다. 면접 시에 아래와 같이 의사소통을 나눌 수 있다.
면접자: 어떤 종류의 처리율 제한 장치를 설계해야 하나요? 클라이언트, 서버 중 어느측 제한 장치 입니까?
면접관: 서버측 API를 위한 장치를 설계한다고 가정합시다.
면접자: 어떤 기준을 사용해서 API 호출을 제어해야 하나요? IP주소를 사용해야 하나요? 아니면 사용자 ID? 아니면 다른 기준이 있습니까?
면접관: 다양한 형태의 제어 규칙을 정의할 수 있도록 하는 유연한 시스템 이어야 합니다.
면접자: 시스템 규모는 어느정도 인가요? 스타트업? 큰 기업인가요?
면접관: 시스템은 대규모 요청을 처리할 수 있어야 합니다.
면접자: 시스템이 분산 환경에서 동작해야 하나요?
면접관: 예
면접자: 처리율 제한 장치는 독립된 서비스인가요? 아니면 애플리케이션 코드에 포함될 수 있나요?
면접관: 그 결정은 본인이 해주시면 되겠습니다.
면접자: 사용자의 요청이 처리율 제한 장치에 의해 걸러진 경우 사용자에게 해당 사싱를 알려야 하나요?
면접관: 예
요구사항
설정된 처리율을 초과하는 요청은 정확하게 제한한다.
낮은 응답시간: 처리율 제한 장치는 HTTP 응답시간에 나쁜 영향을 주어서는 곤란하다.
가능한 한 적은 메모리를 써야 한다.
분산형 처리율 제한 : 하나의 처리율 제한 장치를 여러 서버나 프로세스에서 공유할 수 있어야 한다.
예외 처리 : 요청이 제한되었을 때는 그 사실을 사용자에게 분명하게 보여주어야 한다.
높은 결함 감내성 : 제한 장치에 장애가 생기더라도 전체 시스템에 영향을 주어서는 안된다
면접관과 의사소통을 토대로 위와 같은 요구사항을 정의할 수 있다.
2단계 개략적 설계안 제시 및 동의 구하기
처리율 제한 장치는 어디에 둘 것인가?
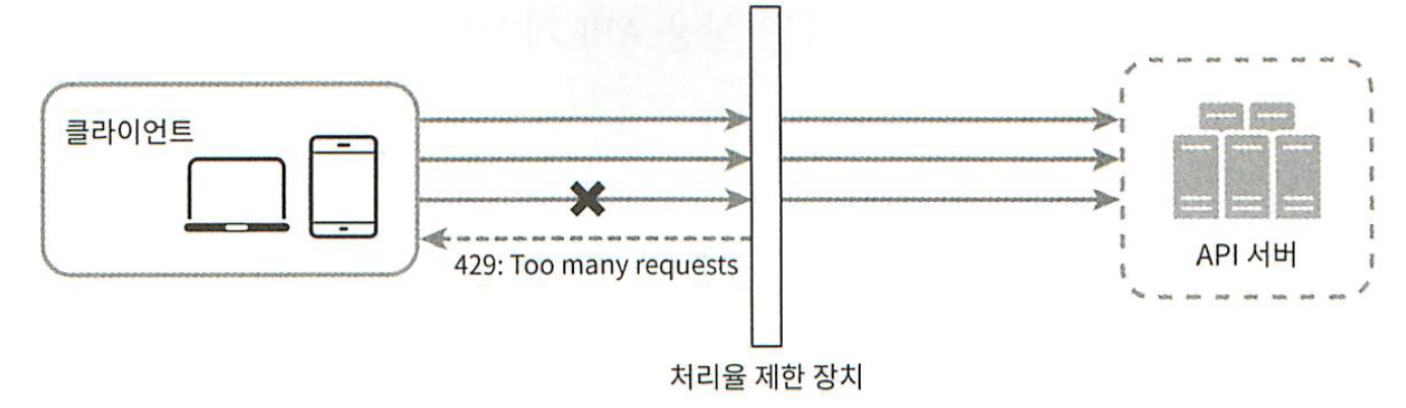
처리율 제한 장치의 위치는 클라이언트, 서버 모두 가능하다. 하지만, 클라이언트 측은 일반적으로 처리율을 제한하는 안정적인 장소가 되지 못한다. 클라이언트 요청은 쉽게 위변조가 가능하기 때문이다. 또한, 모든 클라이언트의 구현을 통제하는 것도 어려울 수 있다. 그렇기 때문에 서버 측에 두는 것이 바람직하다.
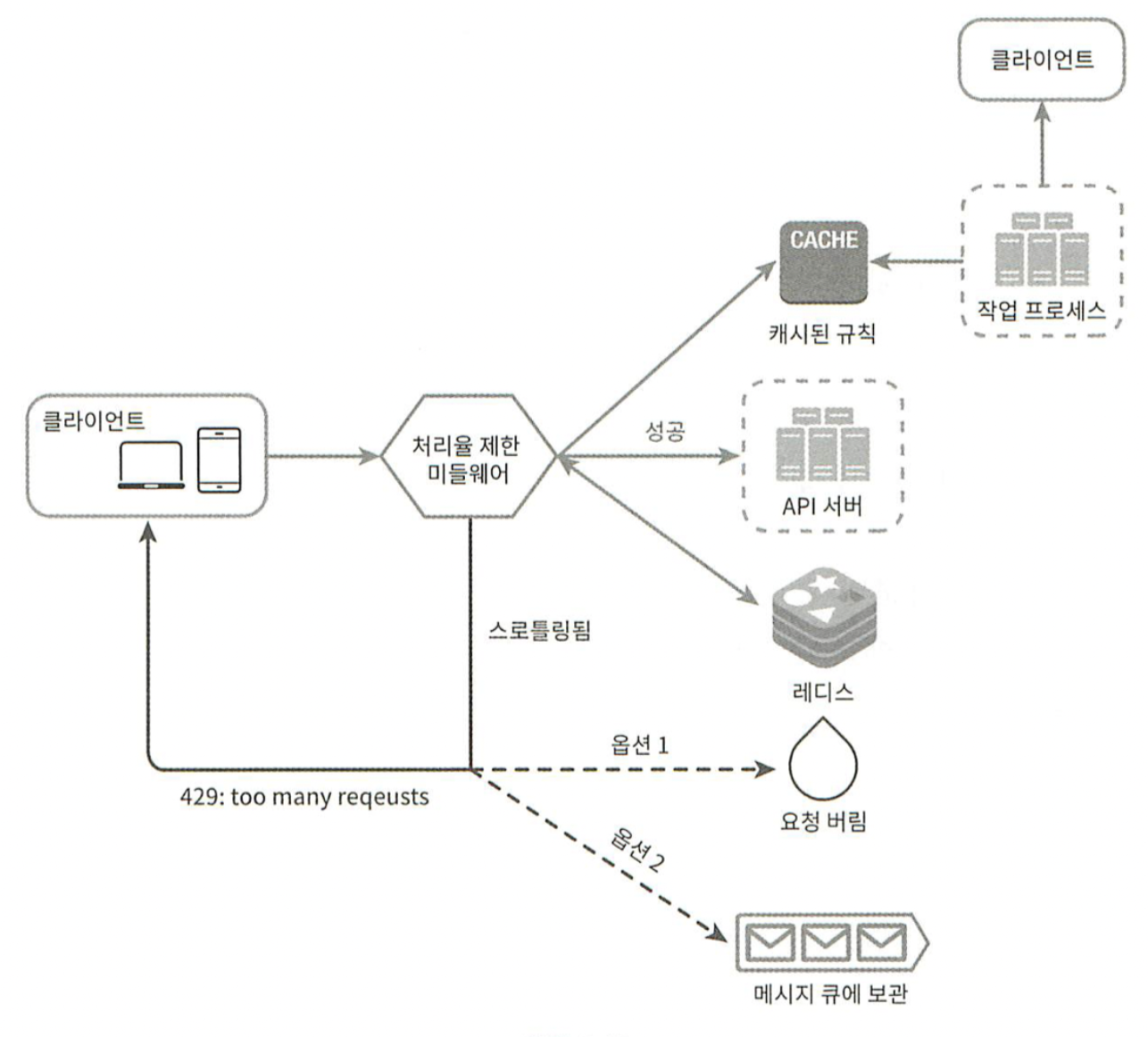
그림 4-1
그림 4-1은 서버 측에 제한 장치를 두는 한 가지 방법이다.
그림 4-2
그림 4-2은 처리율 제한 장치를 API 서버에 두는 대신, 처리율 제한 미들웨어를 만들어 해당 미들웨어로 하여금 API 서버로 가는 요청을 통제하도록 하는 것이다. API 서버의 처리율이 초당 2개로 제한된 상황에서 3개이상 보낸 경우 그림 4-2와 같이 처리될 것이다.
폭넓게 채택된 기술인 클라우드 마이크로서비스 인경우, 처리율 제한 장치는 API 게이트웨이라 불리는 컴포넌트에 구현된다. API 게이트웨이는 처리율 제한, SSL 종단, 사용자 인증, IP 허용 목록 관리 등을 지원하는 완전 위탁관리형 서비스로 클라우드 업체가 유지 보수를 담당하는 서비스다.
그렇다면, 게이트웨이에 처리율 제한 장치를 두는 것이 정답일까? 아니다. 회사 별 기술 스택이나 엔지니어링 인력, 우선순위, 목표에 따라 달라질 수 있기 때문이다. 다만 일반적으로 적용될 수 있는 몇 가지 지침을 나열해 보면 아래와 같다.
프로그래밍 언어, 캐시 서비스 등 현재 사용하고 있는 기술 스택을 점검하라. 현재 사용하는 프로그래밍 언어가 서버 측 구현을 지원하기 충분할 정도로 효율이 높은지 확인하라.
사업 필요에 맞는 처리율 제한 알고리즘을 찾아라. 서버 측에서 모든 것을 구현하기로 했다면, 알고리즘은 자유롭게 선택할 수 있다. 하지만 제3 사업자가 제공하는 게이트웨이를 사용하기로 했다면 선택지는 제한될 수 있다.
여러분의 설계가 마이크로서비스에 기반하고 있고, 사용자 인증이나 IP 허용목록 관리 등을 처리하기 위해 API 게이트웨이를 이미 설계에 포함시켰다면 처리율 제한 기능 또한 게이트웨이에 포함시켜야 할 수도 있다.
처리율 제한 서비스를 직접 만드는 데는 시간이 든다. 처리율 제한 장치를 구현하기에 충분한 인력이 없다면 상용 API 게이트웨이를 쓰는 것이 바람직한 방법일 것이다.
처리율 제한 알고리즘
처리율 제한 알고리즘을 이후에 배우고 싶고, 면접에 대한 단계만 궁금하다면 아래 3단계로 넘어가길 바란다. (저도 정리하고 이후 필요시에 볼 예정입니다.)
이전에 말했 듯, 처리율 제한 알고리즘은 여러가지가 있고 각각 고유의 장단점이 존재한다. 종류 별로는 아래와 같다.
토큰 버킷
누출 버킷
고정 윈도 카운터
이동 윈도 로그
이동 윈도 카운터
각각의 알고리즘의 장단점을 배워보자.
토큰 버킷 알고리즘
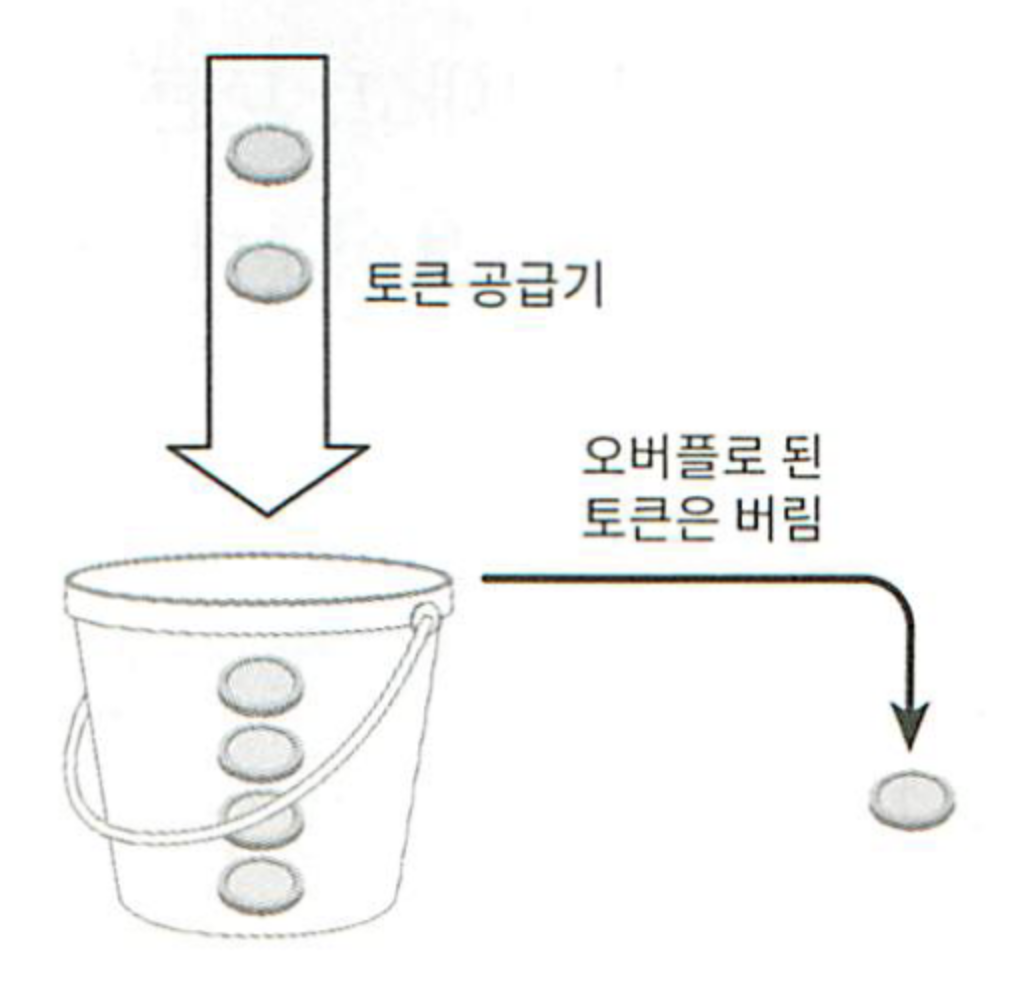
토큰 버킷은 지정된 용량을 갖는 컨테이너이다. 해당 버킷에는 사전 설정된 양의 토큰이 주기적으로 채워진다. 토큰이 꽉 찬 버킷에는 더 이상의 토큰은 추가되지 않는다. AWS와 스트라이프가 API 요청을 통제하기 위해 이 알고리즘을 사용한다.
토큰 버킷 알고리즘은 2개의 인자를 사용한다.
버킷 크기 : 버킷에 담을 수 있는 토큰의 최대 개수
토큰 공급률 : 초당 몇 개의 토큰이 버킷에 공급되는가?
그림 4-3
그림 4-3은 용량이 4인 버킷의 예시이다. 이미 꽉 차 있는데, 토큰이 온다면 유입된 토큰을 버리는 방식이다. 각 요청은 처리될 때마다 하나의 토큰을 사용한다. 요청이 도착하면 버킷에 충분한 토큰이 있는지 검사한다.
그렇다면, 버킷은 몇 개나 사용해야 할까? 이는 공급 제한 규칙에 따라 달라진다. 아래 사례를 살펴보자.
통상적으로, API 엔드포인트마다 별도의 버킷을 둔다. 예를 들어, 사용자마다 하루에 한 번만 포스팅 할 수 있고, 친구는 150명까지 추가할 수 있고, 좋아요 버튼은 5번 까지만 누를 수 있다면, 사용자마다 3개의 버킷을 두어야 할 것이다
IP 주소별로 처리율 제한을 적용해야 한다면, IP 주소마다 버킷을 하나씩 할당해야 한다.
시스템의 처리율을 초당 10,000개 요청으로 제한하고 싶다면, 모든 요청이 하나의 버킷을 공유하도록 해야할 것이다.
토큰 버킷 알고리즘의 장단점으로는 아래와 같다.
장점
구현이 쉽다.
메모리 사용 측면에서 효율적이다.
짧은 시간에 집중되는 트래픽도 처리 가능하다. 남은 토큰이 있기만 하면 요청은 시스템에 전달될 것이다.
단점
버킷 크기와 토큰 공급률이라는 두 개의 인자를 가지고 있는데, 이 값을 적절하게 튜닝하는 것은 까다로운 일이다. (구현이 어렵다는 말 아닌가..?)
누출 버킷 알고리즘
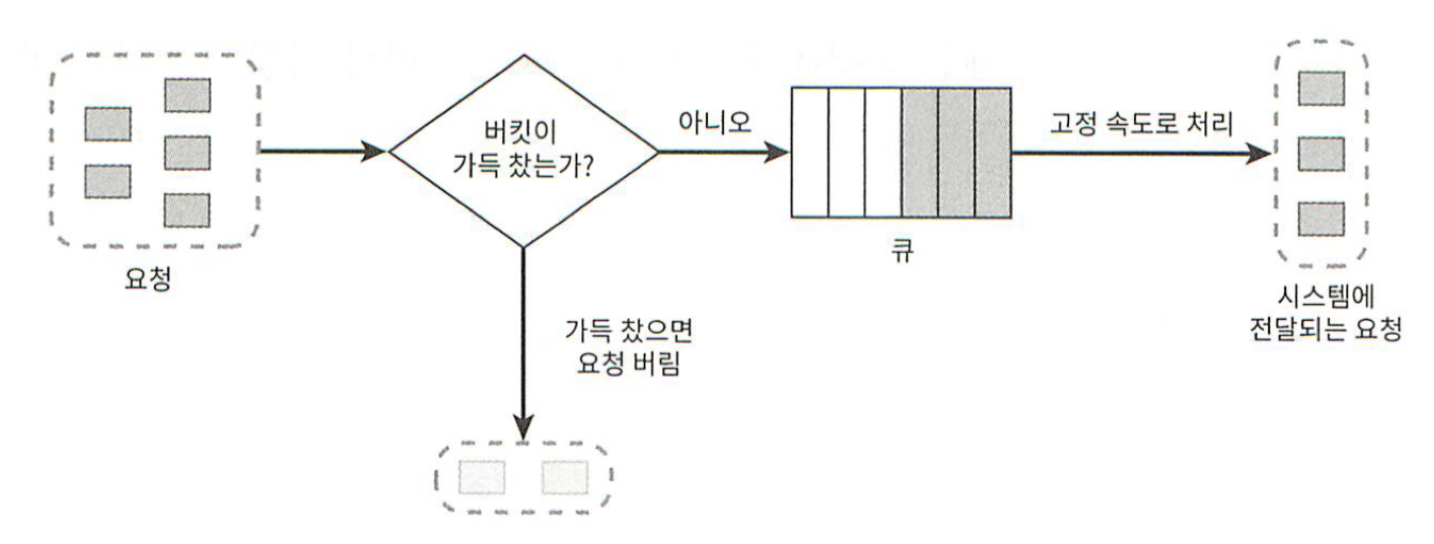
토큰 버킷 알고리즘과 비슷하지만 요청 처리율이 고정되어 있다는 점이 다르다. 누출 버킷 알고리즘은 보통 FIFO로 구현한다.
전자상거래 기업인 쇼피파이가 이 알고리즘으로 처리율 제한을 구현한다. 동작 원리는 아래와 같다.
요청이 도착하면 큐가 가득 차 있는지 본다.
빈자리가 있는 경우에는 큐에 요청을 추가한다.
가득 차 있다면 새 요청을 버린다.
지정된 시간마다 큐에서 요청을 꺼내어 처리한다.
그림 4-4
그림 4-4는 누출 버킷 알고리즘을 도식화한 것이다. 누출 버킷 알고리즘은 토큰 버킷과 같이 아래 2개의 인자를 사용한다.
버킷 크기 : 큐 사이즈와 같은 값이다.
처리율 : 저징된 시간당 몇 개의 항목을 처리할지 지정하는 값이다. 보통 초 단위로 표현한다.
장단점으로는 아래와 같다.
장점
큐의 크기가 제한되어 있어 메모리 사용량 측면에서 효율적이다.
고정된 처리율을 가지고 있기 때문에 안정적 출력이 필요한 경우에 적합하다.
단점
단시간에 많은 트래픽이 몰리는 경우 큐에는 오래된 요청들이 쌓이게 되고, 그 요청들을 제때 처리 못하면 최신 요청들은 버려지게 된다.
두 개 인자를 가지고 있는데, 이들을 올바르게 튜닝하기가 까다로울 수 있다.
고정 윈도 카운터 알고리즘
고정 윈도 카운터 알고리즘은 아래와 같이 동작한다.
타임라인(timeline)을 고정된 간격의 윈도(window)로 나누고, 각 윈도마다 카운터를 붙인다.
요청이 접수될 때마다 이 카운터의 값은 1씩 증가한다.
이 카운터의 값이 사전에 설정된 임계치(threshold)에 도달하면 새로운 요청은 새 윈도가 열릴 때까지 버려진다.
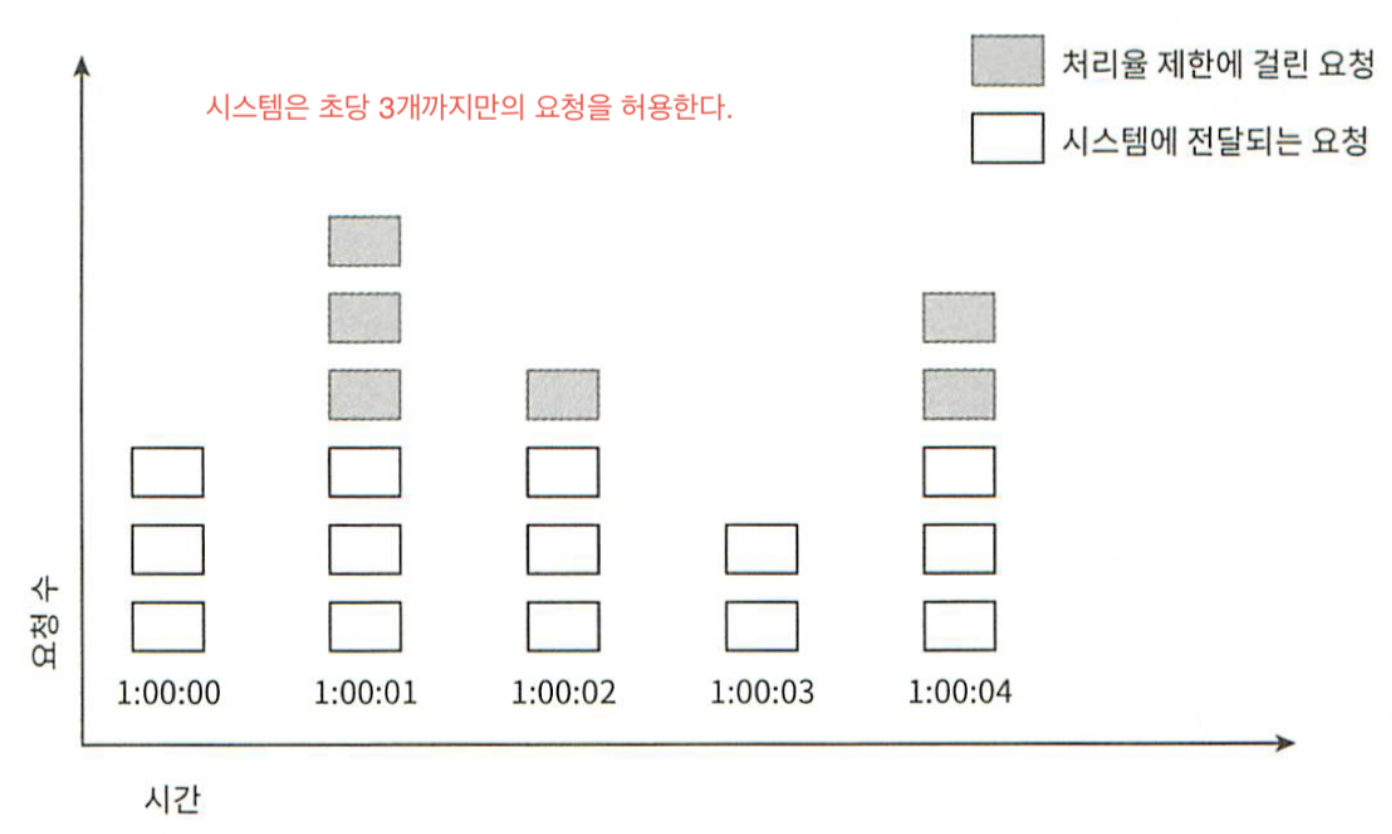
그림 4-5
그림 4-5에서 시간 단위는 1초이다. 시스템은 초당 3개까지의 요청만을 허용하고, 매초마다 열리는 윈도에 3개 이상의 요청이 밀려오면 초과분은 그림 4-5에 보인대로 버려진다.
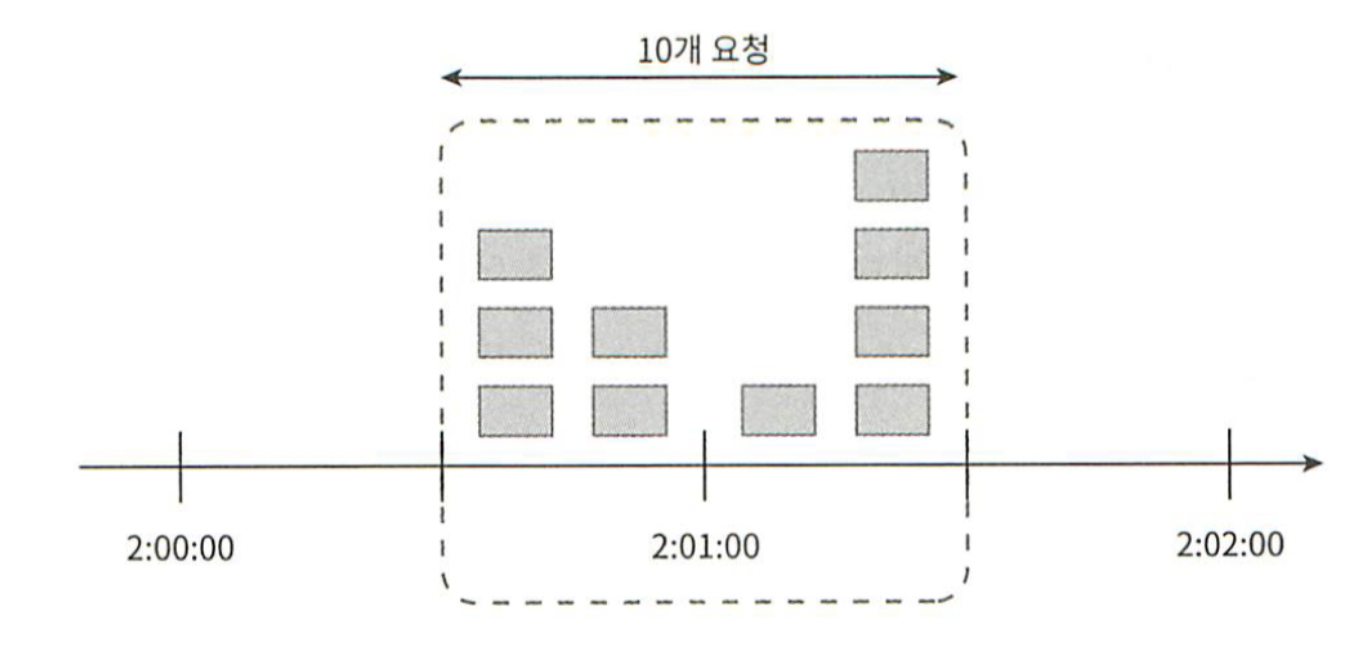
이 알고리즘의 가장 큰 문제는 윈도의 경계 부근에 순간적으로 많은 트래픽이 집중될 경우 윈도에 할당된 양보다 더 많은 요청이 처리될 수 있다는 것이다. 아래 그림 4-6을 살펴보자.
그림 4-6
그림 4-6은 분당 최대 5개의 요청만을 허용하는 시스템이다. 카운터는 매 분마다 초기화 된다. 위를 보면 2:00:00와 2:01:00 사이에 5개의 요청이 들어왔고, 2:01:00과 2:02:00 사이에 또 5개의 요청이 들어왔다. 윈도 위치를 조금 옮겨 2:00:30부터 2:01:30까지의 1분 동안을 보면, 1분동안 처리한 요청은 10개이다. 허용 한도의 2배가 되는 것이다.
장단점으로는 아래와 같다.
장점
메모리 효율이 좋다.
이해하기 쉽다.
윈도가 닫히는 시점에 카운터를 초기화하는 방식은 특정한 트래픽 패턴을 처리하기에 적합하다.
단점
윈도 경계 부근에서 일시적으로 많은 트래픽이 몰려드는 경우, 기대했던 시스템의 처리 한도보다 많은 양의 요청을 처리하게 된다.
이동 윈도 로깅 알고리즘
앞서 살펴본 고정 윈도 카운터 알고리즘에서의 단점을 해결하는 알고리즘이다.
동작 원리는 아래와 같다.
요청의 타임스탬프(timestamp)를 추적한다. 타임스탬프 데이터는 보통 레디스(Redis)의 정렬 집합(sorted set) 같은 캐시에 보관한다.
새 요청이 오면 만료된 타임스탬프는 제거한다. 만료된 타임스탬프는 그 값이 현재 윈도의 시작 시점보다 오래된 타임스탬프를 말한다.
새 요청의 타임스탬프를 로그(log)에 추가한다.
로그의 크기가 허용치보다 같거나 작으면 요청을 시스템에 전달한다. 그렇지 않은 경우에는 처리를 거부한다.
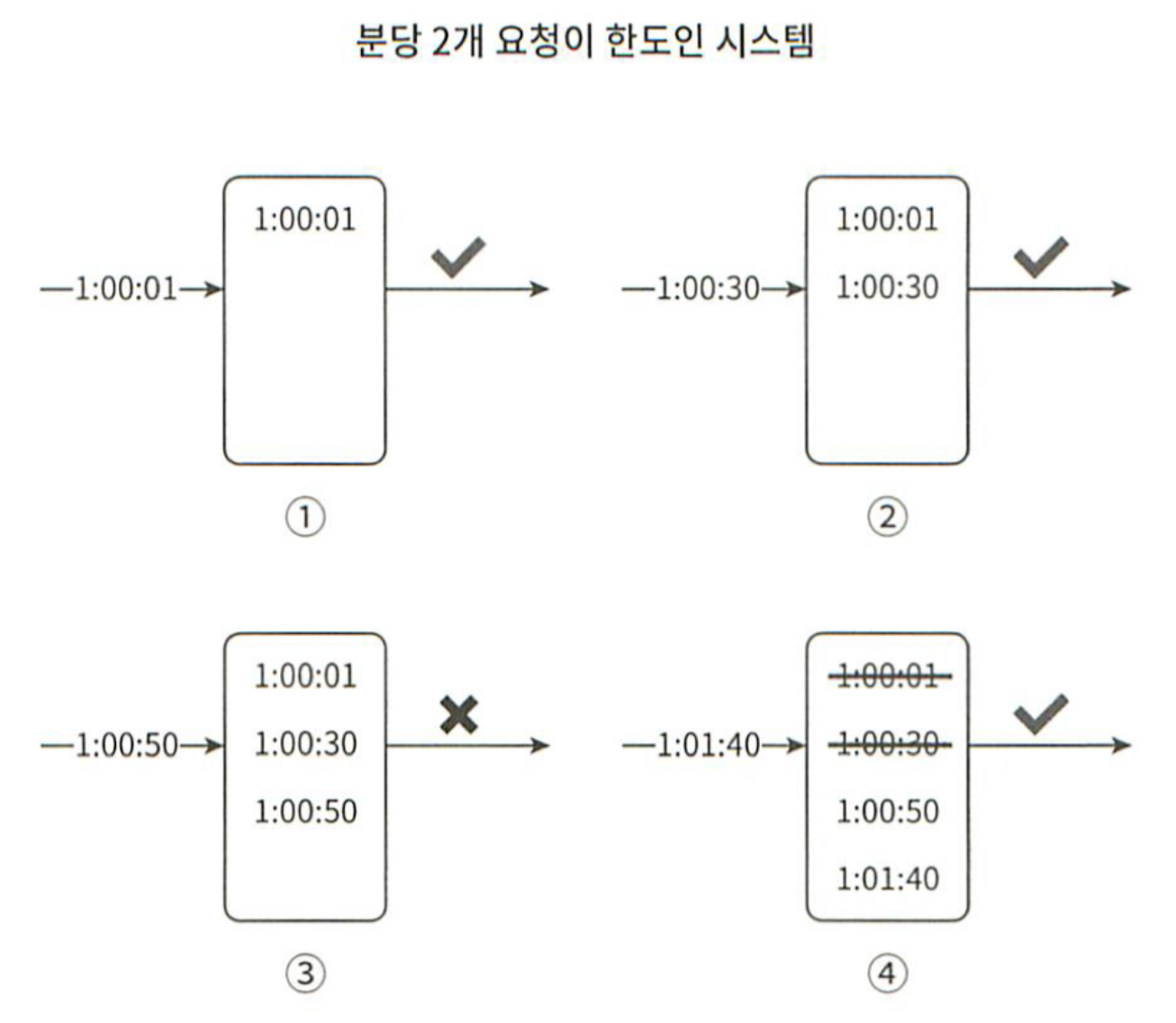
그림 4-7
그림 4-7를 살펴보자.
요청시간이 1:00:01에 도착했을 때, 로그는 비어있는 상태이므로 요청이 시스템에 전달된다.
요청시간이 1:00:30에 도착했을 때, 타임스탬프가 로그에 추가된다. 직후 크기는 2이며, 허용 한도보다 크지 않기 때문에 요청이 시스템에 전달된다.
요청 시간이 1:00:50에 도착했을 때, 타임스탬프가 로그에 추가된다. 직후 크기는 3이며, 허용 한도보다 크기 때문에 요청이 시스템에 전달되지 않는다.
요청 시간이 1:01:40에 도착했을 때, 타임스탬프가 로그에 추가된다. [1:00:01, 1:00:30]은 1분이 지났기 때문에 만료되었기 때문에 삭제한다. 삭제 직후 로그의 크기는 2이며, 허용 한도보다 크지 않기 때문에 요청이 시스템에 전달된다.
장단점을 살펴보자.
장점
알고리즘이 구현하는 처리율 제한 메커니즘이 매우 정교하다.
단점
알고리즘이 다량의 메모리를 사용한다. 거부된 요청의 타임스탬프도 보관되기 때문이다.
이동 윈도 카운터 알고리즘
고정 윈도 카운터 알고리즘과 이동 윈도 로깅 알고리즘을 결합한 알고리즘
해당 알고리즘을 구현하는데는 2가지 접근법이 사용될 수 있는데, 책에는 1가지만 설명하고 다른 하나는 참고문헌을 언급한다.
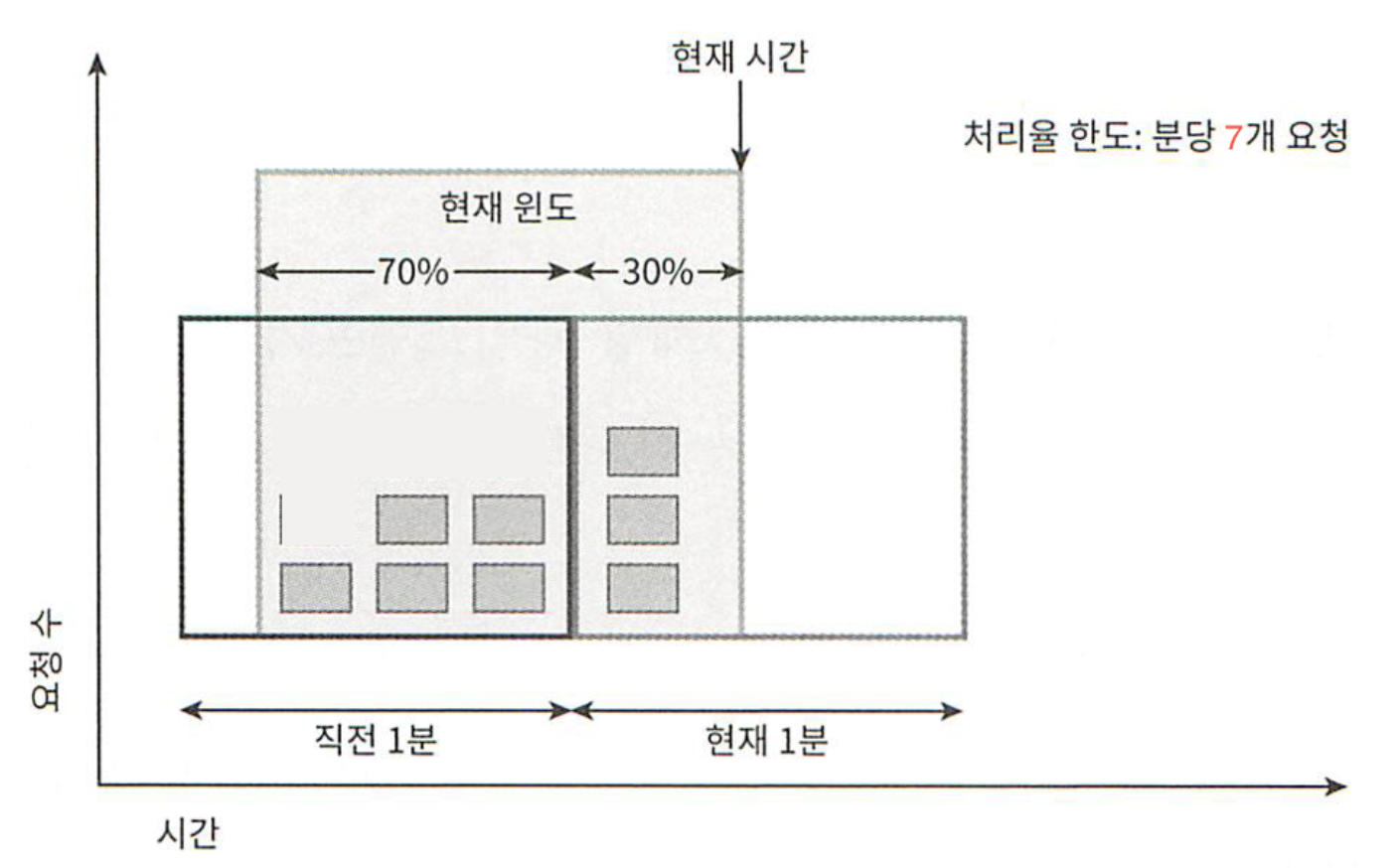
그림 4-8
그림 4-8은 분당 7개 요청으로 설정되어 있다. 이전 1분 동안 5개의 요청이, 그리고 이후 1분동안 3개의 요청이 왔다고 가정되어 있다. 현재 1분의 30% 시점에 도착한 새 요청의 경우, 현재 윈도에 몇 개의 요청이 온 것으로 보고 처리해야 할까? 아래와 같이 계산한다.
현재 1분간의 요청 수 + 직전 1분간의 요청 수 * 이동 윈도와 직전 1분이 겹치는 비율
위의 공식대로 하면, 현재 윈도에 들어있는 요청은 3+5*70%=6.5개다. 반올림, 반내림하여 쓸 수 있는데, 본 예제에서는 내림하여 쓴다고 한다. 따라서 값은 6이다.
현재 1분의 30% 시점에 도착한 신규 요청은 시스템으로 전달될 것이다. 하지만 그 직후에는 한도에 도달하였으므로 더 이상의 요청은 받을 수 없다.
장단점을 살펴보자.
장점
이전 시간대의 평균 처리율에 따라 현재 윈도의 상태를 계산하므로 짧은 시간에 몰리는 트래픽에도 대응 가능하다.
메모리 효율이 좋다.
단점
직전 시간대에 도착한 요청이 균등하게 분포되어 있다고 가정한 상태에서 추정치를 계산하기 때문에 다소 느슨하다. 하지만, 이 문제는 크게 심각하지는 않다. 클라우드플레어가 실시했던 실험에 따르면 40억 개의 요청 가운데 시스템의 실제 상태와 맞지 않게 허용되거나 버려진 요청은 0.003%에 불과했기 때문이다.
개략적인 아키텍처
처리율 제한 알고리즘의 기본 아이디어는 단순하다. 얼마나 많은 요청이 접수되었는지를 추적할 수 있는 카운터를 추적 대상별로 두고(사용자? IP?, API 엔드포인트? 서비스 단위?), 이 카운터의 값이 어떤 한도를 넘어서면 한도를 넘어 도착한 요청은 거부하는 것이다.
그렇다면, 이 카운터응 어디에 보관하는 것이 적당할까? 데이터베이스는 디스크 접근 때문에 느려 사용하면 안 된다. 메모리상에서 동작하는 캐시가 바람직한데, 빠른데다 시간에 기반한 만료 정책을 지원하기 때문이다. 일례로 레디스는 처리율 제한 장치를 구현할 때 자주 사용되는 메모리 기반 저장장치로서, INCR과 EXPIRE의 두 가지 명령어를 지원한다.
INCR : 메모리에 저장된 카운터의 값을 1만큼 증가시킨다.
EXPIRE : 카운터에 타움아웃 값을 설정한다. 설정된 시간이 지나면 카운터는 자동으로 삭제된다.
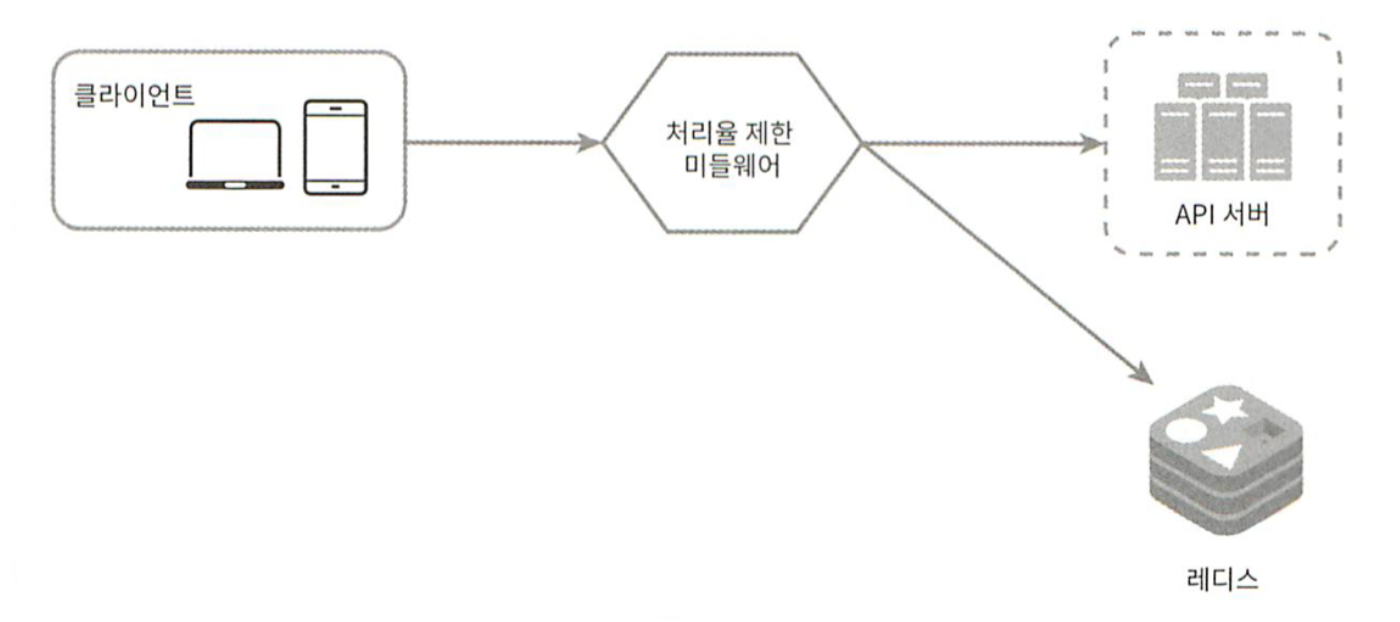
그림 4-9
그림 4-9는 처리율 제한 장치의 개략적인 구조이다.
3단계 상세 설계
그림 4-9의 개략적 설계를 봐서는 아래와 같은 사항은 알 수가 없다.
처리율 제한 규칙은 어떻게 만들어지고 어디에 저장되는가?
처리가 제한된 요청들은 어떻게 처리되는가?
해당 절에서는 처리율 제한 규칙에 관한 질문부터 답한 후, 처리가 제한된 요청의 처리 전략을 살펴본다. 그리고 마지막으로 분산 환경에서의 처리율 제한 기법에 대해서도 살펴보고, 구체적인 설계와 성능 최적화 방안, 모니터링 방안까지 살펴볼 것이다.
처리율 제한 규칙
리프트(Lyft)는 처리율 제한에 오픈 소스를 사용하고 있다. 이 컴포넌트를 들여다보고, 어떤 처리율 제한 규칙이 사용되고 있는지 살펴보자.
domain : messaging
descriptors :
- key : message_type
value : marketing
rate_limit :
unit : day
requests_per_unit: 5
위의 예제는 시스템이 처리할 수 있는 마케팅 메시지의 최대치를 하루 5개로 제한하고 있다. 아래는 또 다른 규칙의 사례다.
domain : auth
descriptors :
- key : auth_type
value : login
rate_limit :
unit : minute
requests_per_unit: 5
위 규칙은 클라이언트가 분당 5회 이상 로그인 할 수 없도록 제한하고 있다. 이런 규칙들은 보통 설정 파일(configuration file) 형태로 디스크에 저장된다.
처리율 한도 초과 트래픽의 처리
어떤 요청이 한도 제한이 걸리면 API는 HTTP 429 Status Code(too many requests)를 클라이언트에게 보낸다. 경우에 따라서는 한도 제한에 걸린 메시지를 나중에 처리하기 위해 큐에 보관할 수도 있다. 예를 들어, 어떤 주문이 시스템 과부하때문에 한도 제한에 걸렸다고 해보자. 해당 주문들은 보관했다가 나중에 처리할 수도 있을 것이다.
처리율 제한 장치가 사용하는 HTTP Header
클라이언트는 자기 요청이 처리율 제한에 걸리고 있는지를(throttle) 어떻게 감지할 수 있을까? 자기 요청이 처리율 제한에 걸리기까지 얼마나 많은 요청을 보낼 수 있는지 어떻게 알 수 있을까? 답은 HTTP 응답 헤더에 있다.
X-Ratelimit-Remaining : 윈도 내에 남은 처리 가능 요청의 수
X-Ratelimit-Limit : 매 윈도마다 클라이언트가 전송할 수 있는 요청의 수
X-Ratelimit-Retry-After : 한도 제한에 걸리지 않으려면 몇 초 뒤에 요청을 다시 보내야 하는지 알림
사용자가 너무 많은 요청을 보내면 429 too many requests 오류를 X-Ratelimit-It-Retry-After 헤더와 함께 반환하도록 한다.
상세 설계
4-10
그림 4-10은 상세한 설계 도면이다.
처리율 제한 규칙은 디스크에 보관한다. 작업 프로세스(workers)는 수시로 규칙을 디스크에서 읽어 캐시에 저장한다.
클라이언트가 요청을 서버에 보내면 요청은 먼저 처리율 제한 미들웨어에 도달한다.
처리율 제한 미들웨어는 제한 규칙을 캐시에서 가져온다. 아울러 카운터 및 마지막 요청의 타임스탬프를 레디스 캐시에서 가져온다. 가져온 값들에 근거하여 해당 미들웨어는 API 서버로 클라이언트의 요청을 보낼지, 클라이언트에게 429 응답할지 선택한다.
분산 환경에서의 처리율 제한 장치의 구현
단일 서버를 지원하는 처리율 제한 장치를 구현하는 것은 어렵지 않다. 하지만 여러 대의 서버와 병렬 스레드를 지원하도록 시스템을 확장하는 것은 또 다른 문제다. 아래 2가지 어려운 문제를 풀어야 한다.
경쟁 조건 (race condition)
동기화 (synchronization)
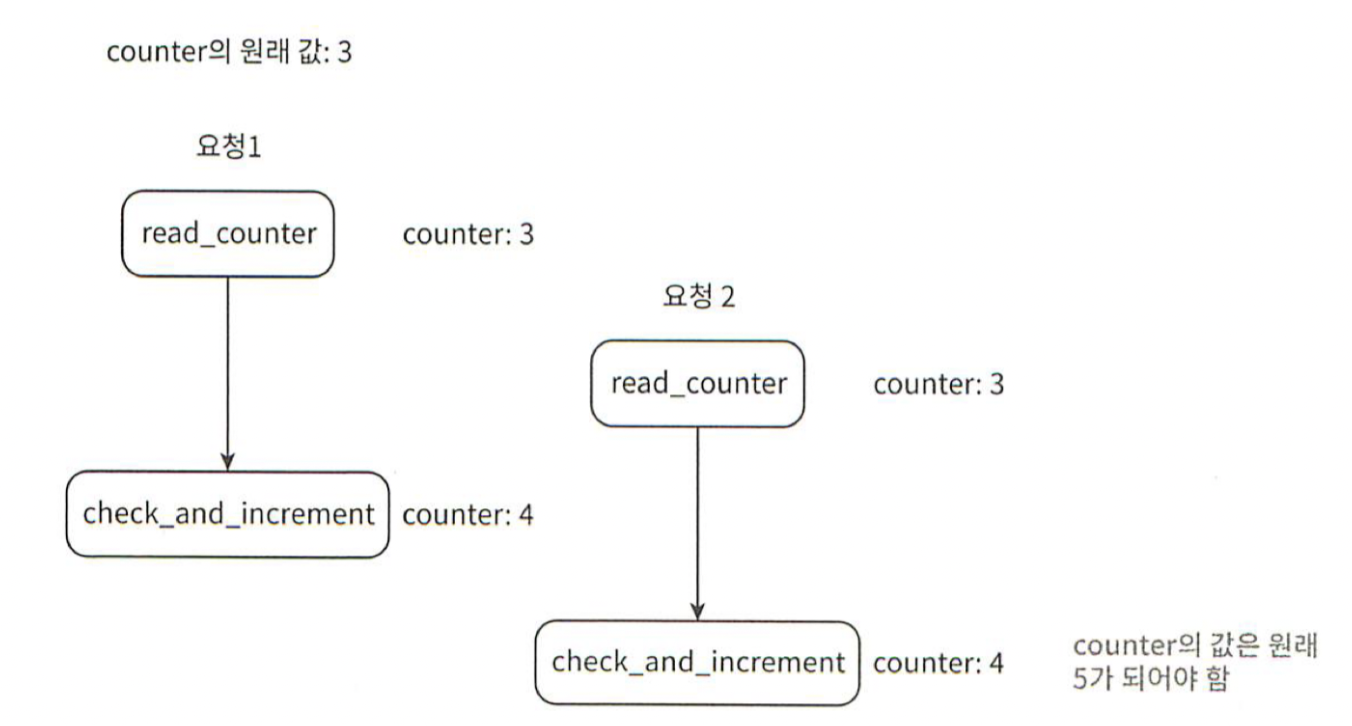
경쟁조건
처리율 제한 장치는 대략적으로 아래와 같이 동작한다.
레디스에서 카운터의 값을 읽는다.
counter+1의 값이 임계치를 넘는지 본다.
넘지 않는다면 레디스에 보관된 카운터 값을 1만큼 증가시킨다.
하지만, 병행성이 심한 환경에서는 그림 4-11 같은 경쟁 조건 이슈가 발생할 수 있다.
그림 4-11
레디스에 저장된 counter의 값을 비슷한 시간대에 2개의 스레드에서 병렬적으로 counter의 값을 읽고 처리할 때 문제가 발생할 수 있다. 이때, 가장 널리 알려진 해결책은 락(lock)이다. 하지만, 락은 시스템의 성능을 상당히 떨어뜨린다는 문제가 있다. 위 설계의 경우에는 lock대신 쓸 수 있는 해결책이 2가지 있다.
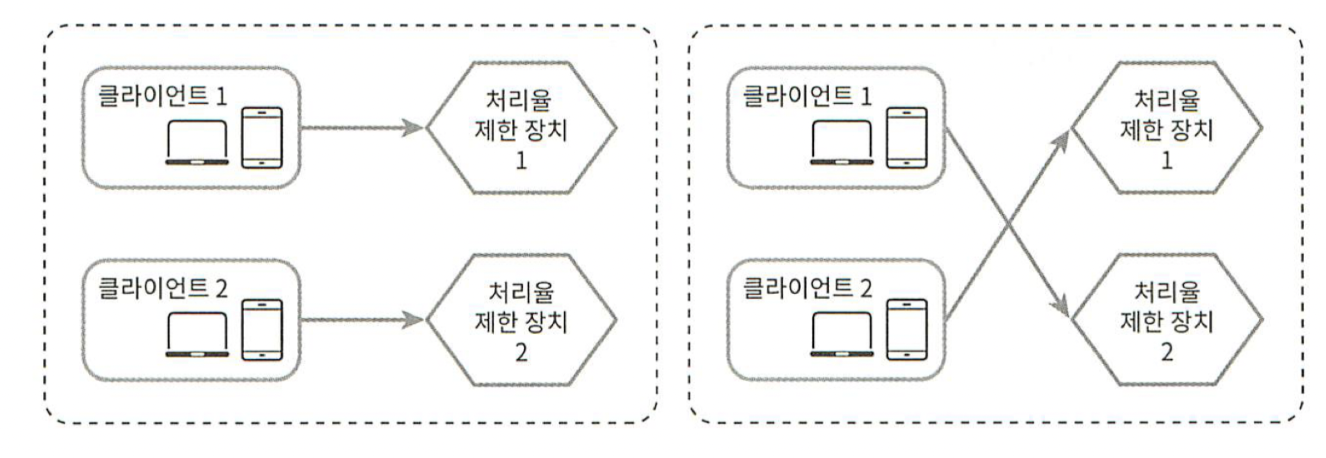
동기화는 분산 환경에서 고려해야 할 중요한 요소이다. 수백만 사용자를 지원하려면 한 대의 처리율 제한 장치 서버로는 충분하지 않을 수 있다. 그렇기때문에 처리율 제한 장치 서버를 여러 대 두게 되면 동기화가 필요해진다.
그림 4-12
예를들어, 그림 4-12의 왼쪽 그림의 경우 클라이언트 1은 제한 장치 1에 요청을 보내고 클라이언트 2는 제한 자치 2에 요청을 보내고 있다. 웹 계층은 무상태(stateless)이므로 클라이언트는 그림 4-12의 오른쪽 그림처럼 각기 다른 제한 장치로 보내질 수 있다. 이때 동기화를 하지 않는다면 제한 장치 1은 클라이언트 2에 대해서는 아무것도 모르므로 처리율 제한을 올바르게 수행할 수 없을 것이다.
이에 대한 1가지 해결책은 고정 세션(sticky session)을 활용하여 같은 클라이언트로부터의 요청은 항상 같은 처리율 제한 장치로 보낼 수 있도록 하는 것이다. 하지만 이 방법은 추천하고 싶지 않은데, 규모면에서 확장 가능하지도 않고 유연하지도 않기 때문이다.
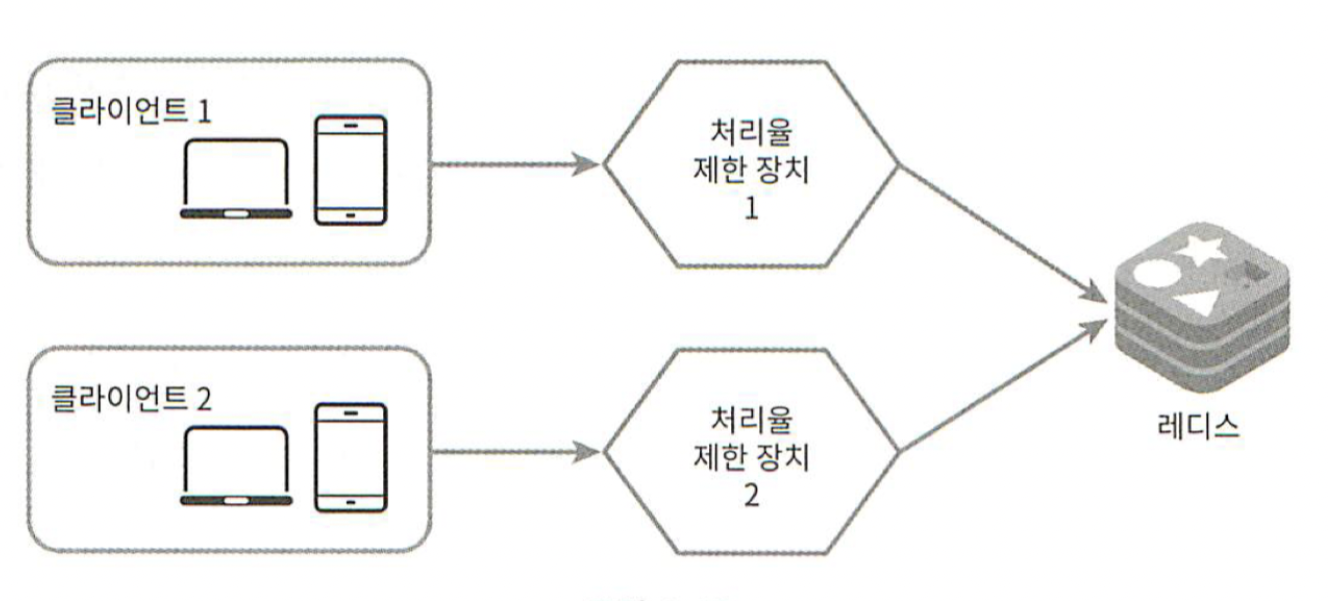
그림 4-13
더 나은 해결책으로는 그림 4-13 같이 레디스와 같은 중앙 집중형 데이터 저장소를 쓰는 것이다.
성능 최적화
지금까지 살펴본 설계는 2가지 지점에서 개선이 가능하다.
우선, 여러 데이터센터를 지원하는 문제는 처리율 제한 장치에 매우 중요한 문제라는 것을 상기하자. 데이터센터에서 멀리 떨어진 사용자를 지원하려다보면 지연시간(latency)이 증가할 수 밖에 없기 때문이다. 대부분의 클라우드 서비스 사업자는 세계 곳곳에 에지 서버(edge server)를 심어놓고 있다. 사용자의 트래픽을 가장 가까운 에지 서버로 전달하여 지연시간을 줄인다.
2번째로, 제한 장치 간에 데이터를 동기화할 때 최종 일관성 모델(eventual consistency model)을 사용하는 것이다. 이 일관성 모델이 생소하다면, 이후 6장 "키-값 저장소 설계"의 "데이터 일관성" 항목을 참고하도록 하자. (나도 생소하기 때문에 이후에 확인해봐야겠다.)
모니터링
처리율 제한 장치를 설치한 이후에는 효과적으로 동작하고 있는지 보기 위해 데이터를 모을 필요가 있다. 기본적으로 모니터링을 통해 확인하려는 것은 아래 2가지이다.
채택된 처리율 제한 알고리즘이 효과적이다.
정의한 처리율 제한 규칙이 효과적이다.
예를들어, 처리율 제한 규칙이 너무 빡빡하게 설정되었다면 많은 유효 요청이 처리되지 못하고 버려질 것이다. 이러한 현상이 일어난다면 규칙을 완화할 필요가 있다. 또한, 깜짝 세일 같은 이벤트 때문에 트래픽이 급증할 때 처리율 제한 장치가 비효율적으로 동작한다면, 특정 트래픽 패턴을 잘 처리할 수 있도록 알고리즘을 바꾸는 것을 고려해봐야 한다. 이러한 상황에서는 토큰 버킷이 적합할 것이다.
이처럼 모니터링을 통해 서비스의 질을 향상시킬 수 있다.
4단계 마무리
살펴본 처리율 제한 알고리즘은 아래와 같다.
토큰 버킷
누출 버킷
고정 윈도 카운터
이동 윈도 로그
이동 윈도 카운터
알고리즘 이외에도 아키텍처, 분산환경에서의 처리율 제한 장치, 성능 최적화, 모니터링 등을 살펴보았다. 시간이 허락된다면 아래와 같은 부분을 언급해보면 도움이 될 것이다.
경성(hard) 또는 연성(soft) 처리율 제한
경성 처리율 제한 : 요청 개수는 임계치를 절대 넘어설 수 없다.
연성 처리율 제한 : 요청 개수는 잠시 동안은 임계치를 넘어설 수 있다.
다양한 계층에서의 처리율 제한
이번 장에서는 애플리케이션 계층에서의 처리율 제한에 대해서만 살펴보았다. 하지만, 다른 계층에서도 처리율 제한이 가능하다. 예를들어, Iptables를 사용하면 IP 주소(3계층)에 처리율 제한을 적용하는 것이 가능하다.
처리율 제한을 회피하는 방법. 클라이언트를 어떻게 설계하는 것이 최선인가?
클라이언트 측 캐시를 사용하여 API 호출 횟수를 줄인다.
처리율 제한의 임계치를 이해하고, 짧은 시간 동안 너무 많은 메시지를 보내지 않도록 한다.
예외나 에러를 처리하는 코드를 도입하여 클라이언트가 예외적으로 상황으로부터 우아하게 복구될 수 있도록 한다.
현재의 층수인 int 형이 주어지고 이를 +-10^n층을 옮겨 다니며 0층으로 이동하는 최수 횟수를 구하는 것이다. 10^n층을 옮기는데 1의 횟수가 추가된다.
입력
현재 층수가 입력으로 주어진다.
1 <= storey <= 100,000,000
풀이
10^0의 값인 1층부터 0으로 맞추며 storey값이 0이 될 때까지 %10, /=10을 해주며 구하면 된다고 생각했다.
5층 이하인 경우 현재 1의 자리 층수만을 더 해준다.
answer += rest;
6층 이상인 경우 (10-현재 1의 자리 층수)만을 더 해주며 storey에 1을 더해준다.
answer += (10-rest); storey++;
오답 코드
class Solution {
public int solution(int storey) {
int answer = 0;
while(storey != 0) {
int rest = storey%10;
storey /= 10;
if(rest <= 5) {
answer += rest;
} else {
storey++;
answer += (10-rest);
}
}
return answer;
}
}
하지만, 해당 코드는 정확도에서 문제가 발생했다.
문제는 1의 자리 수가 5일 때 발생한다. 만약, storey 값이 55라고 가정해보자. +5를 해도, -5를 해도 총 횟수는 10으로 문제가 발생하지 않는다. 하지만, storey 값이 195라고 가정해보자. +5를 하면 200이되고 총 7번만에 0층으로 간다. 하지만, -5를 하면 총 8번만에 0층으로 간다.
위의 문제를 해결하는 방법은 1의 자리 수가 5인 경우 10을 나눈 storey 값의 1의 자리 수가 5 이상인 경우 아래의 작업을 해야한다.
꿈꾸던 회사의 면접 기회가 왔다고 상상해보자. 그런데 면접 세션에 "시스템 설계 면접"이 적혀있다. 시스템 설계는 수백 명, 수천 명의 엔지니어들이 참여하여 개발한 제품일 것이다. 하지만, 1시간안에 1명의 면접자가 완벽하게 설계할 수 있을까? 정답은 아니다.
그렇다면, 왜 시스템 설계 면접이 있을까? 시스템 설계 면접은 두 명의 동료가 모호한 문제를 풀기 위해 협력하여 해결책을 찾아내는 과정에 대한 시뮬레이션이다. 당연하게도 문제는 정답이 없다. 최종적으로 도출된 설계안은 설계 과정에 들인 노력에 비하면 중요하지 않다. 그렇다. 설계 과정을 토대로 면접자의 기술적 측면, 협력, 탈압박, 문제해결능력 등 다양한 능력을 확인할 수 있다.
목표
시스템 설계 면접에 관한 팁들을 살펴보고, 면접을 공략하는 효과적인 접근법을 배워보자.
효과적 면접을 위한 4단계 접근법
시스템 설계 면접은 정답이 없지만 절차나 범위에는 공통적인 부분이 있다.
1단계 문제 이해 및 설계 범위 확정
엔지니어인 우리에게는 어려운 문제를 풀고 최종 설계를 바로 내놓고 싶은 욕구가 있다. 하지만, 그러면 잘못된 시스템을 설계할 가능성이 높아진다. 엔지니어가 가져야할 가장 중요한 기술 중 하나는 올바른 질문을 하는 것, 적절한 가정을 하는 것, 그리고 시스템 구축에 필요한 정보를 모으는 것이다.
질문을 던지면 면접관을 여러분이 질문에 대한 답을 바로 내놓거나, 여러분 스스로 어떤 가정을 하기를 주문할 것이다. 후자의 경우에는 그 가정을 화이트보드나 종이에 적어두어야 한다. 나중에 필요해질 때가 있기 때문이다.
그렇다면, 어떤 질문을 해야할까? 요구사항을 정확히 이해하는 데 필요한 질문을 하자. 아래는 그 예시가 될 수 있다.
구체적으로 어떠 기능들을 만들어야 하는가?
제품 사용자 수는 얼마나 되나?
회사의 규모는 얼마나 빨리 커지리라 예상하나? 3달, 반년, 1년 뒤 예상 규모는 어느 정도인가?
정렬이 필요한가?
2단계 개략적인 설계안 제시 및 동의 구하기
개략적인 설계안이 나왔다면, 면접관의 동의를 구하자. 해당 과정은 면접관과 협력하며 진행하면 좋다.
설계안에 대한 최초 청사진을 제시하고 의견을 구하라. 면접관이 마치 팀원인 것처럼 행동해라. 훌륭한 면접관은 지원자와 대화하고 설계 과정에 개입하는 것을 즐긴다.
화이트보드나 종이에 핵심 컴포넌트를 포함하는 다이어그랩을 그려라. 클라이언트, API, 웹서버, 데이터 저장소, 캐시, CDN, 메시지 큐 같은 것들이 포함될 수 있을 것이다.
최초 설계안이 시스템 규모에 관계된 제약사항들을 만족하는지 개략적으로 계산해보자. 계산 과정을 소리 내어 설명해라. 아울러, 이런 개략적 추정이 필요한지는 면접관에게 미리 물어보자.
가능하다면 시스템의 구체적 사용 사례도 몇 가지 살펴보자. 고려하지 못한 edge case를 발견하는 데 도움이 되기 때문이다.
예제
뉴스 피드 시스템을 설계하라고 했다고 가정해보자. 시스템이 실제로 어떻게 동작하는지 지금 당장 이해할 필요는 없다. 상세한 내용은 11장에서 설명한다고 한다.
개략적으로 살펴보면 2가지의 처리 flow인 feed 발행, feed 생성을 나눠 생각해볼 수 있다.
피드 발행
사용자가 포스트를 올리면 관련된 데이터가 캐시/데이터베이스에 기록되고, 해당 사용자의 친구 뉴스 피드에 뜨게 된다.
피드 생성
어떤 사용자의 뉴스 피드는 해당 사용자 친구들의 포스트를 시간 역순으로 정렬하여 만든다.
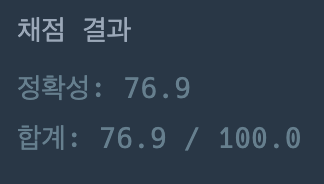
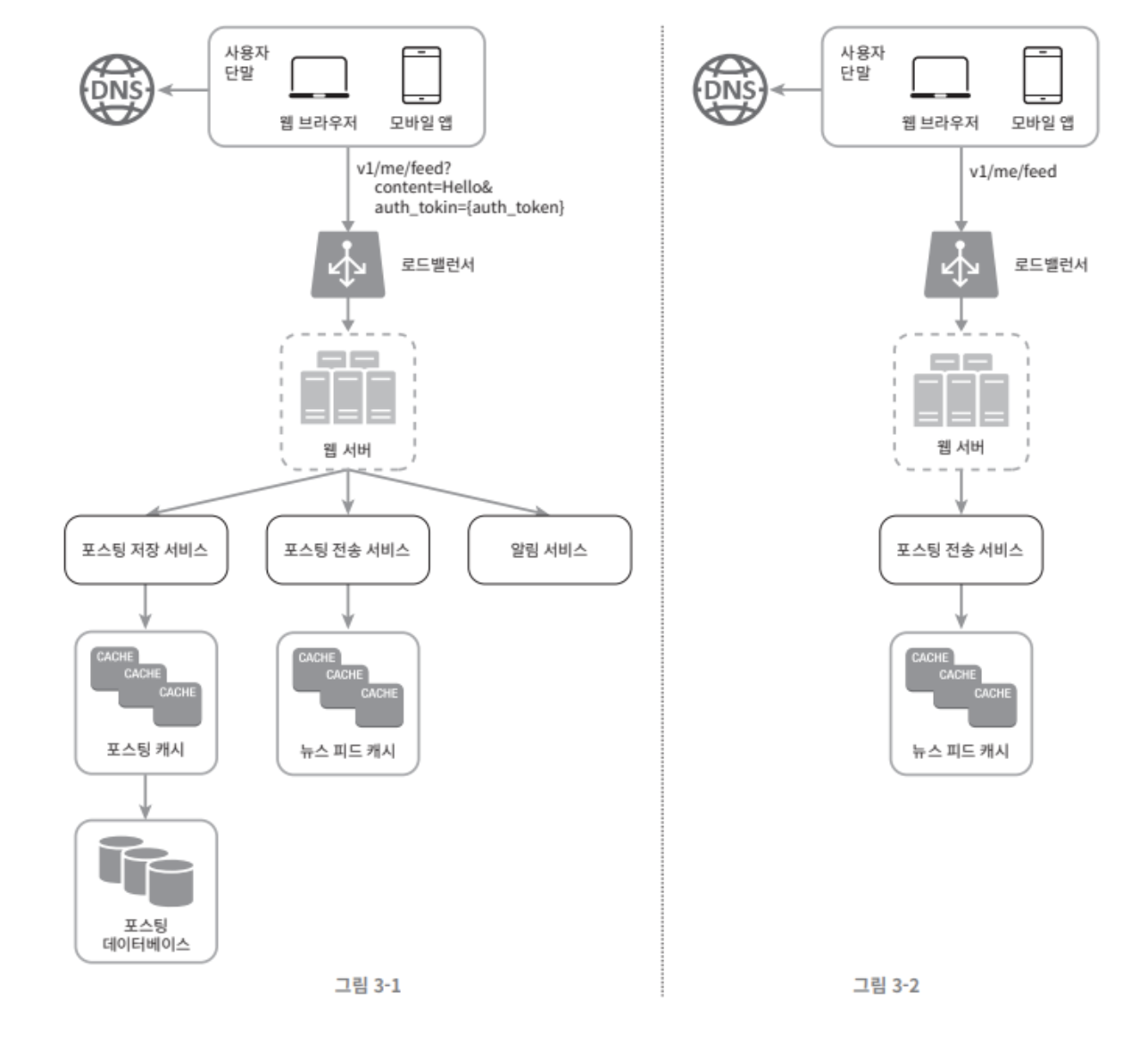
그림 3-1과 3-2는 피드 출력과 피드 생성 플로를 각각 개략적으로 그린 것이다.
3단계 상세 설계
이제 면접관과 해야할 일은 컴포넌트 사이의 우선순위를 정하는 것이다. 어떨 때는 면접관이 면접자가 집중 했으면 하는 영역을 알려주기도 한다. 어떨 때는, 시스템의 성능 특성에 대한 질문을 던질 것이고, 해당 경우 질문 내용은 시스템의 병목 구간이나 자원 요구량 추정치에 초점이 맞춰져 있을 것이다. 대부분의 면접관은 면접자가 특정 시스템 컴포넌트들의 세부사항을 깊이 있게 설명하는 것을 보길 원한다. 가령 문제가 단축 URL 생성기(URL shortener) 설계에 관한 것이었다고 해 보자. 그렇다면, 면접관은 해시 함수의 설계를 구체적으로 설명하는 것을 듣고 싶어할 것이다. 채팅 시스템에 관한 문제였다면, 어떻게 하면 지연시간(latency)을 줄이고 사용자의 온/오프라인 상태를 표시할 것인지를 듣고자 할 것이다.
면접 시에는 시간 관리에도 특별히 주의를 기울여야 한다. 사소한 세부사항을 설명하느라 정작 능력을 보일 기회를 놓쳐버리게 될 수도 있기때문이다. 면접자는 면접관에게 긍정적인 시그널(signal)을 전달하는 데 집중해야 한다. 불필요한 세부사항에 시간을 쓰지 말자.
예제
뉴스 피드 시스템의 개략적 설계를 마친 사항이라 해보자. 또한, 면접관도 해당 설계에 몬작하고 있다고 가정하자. 이제 아래 두 가지 중요한 용례를 보다 깊이 탐구해야 한다.
피드 출력
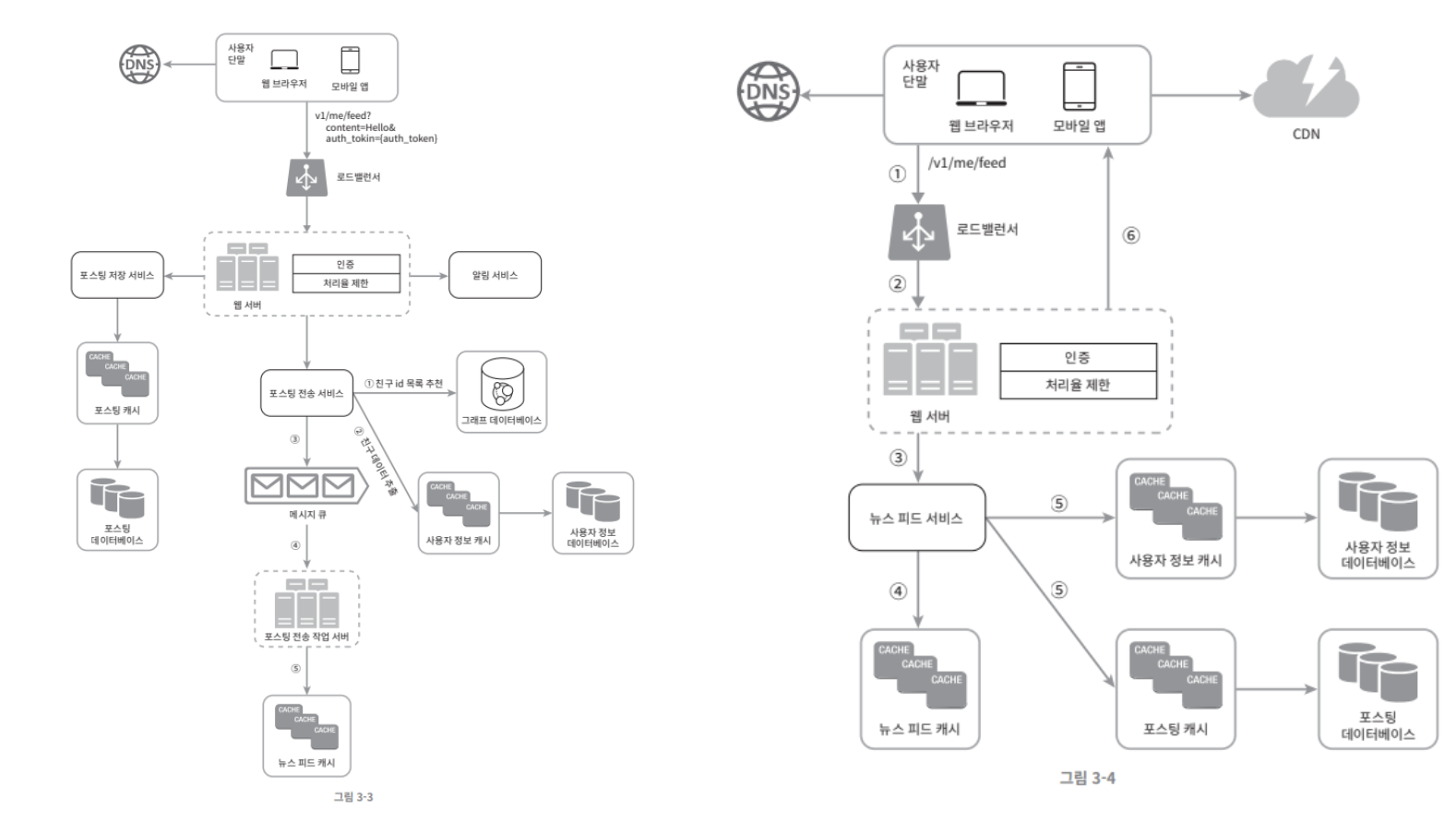
뉴스 피드 가져오기
위 그림은 각각에 대한 상세 설계이다. 해당 설계안에 대해서는 11장에서 보다 깊이 설명한다.
4단계 마무리
이제 면접관은 설계 결과물에 관련한 몇 가지 후속 질문을 던질 수도 있고 면접자가 스스로 추가 논의를 진행하도록 할 수도 있다. 아래 몇 가지 지침을 활용하도록 하자.
면접관이 좀 더 개선 가능한 지점을 찾아내라 주문할 수도 있다. 이때, 개선할 부분이 없다는 답은 하지 않도록 하자. 개선할 점은 언제나 있기 마련이다.
만든 설계를 한 번 다시 요약해주는 것도 도움이 될 수 있다. 여러 해결책을 제시한 경우에는 특히 중요하다. 긴 면접 세션이 끝난 뒤에 면접관의 기억을 환기시켜주는 효과가 있기때문이다.
오류가 발생하면 무슨 일이 생기는지 따져보면 흥미로울 것이다.
운영 이슈도 논의할 가치가 충분하다. 메트릭은 어떻게 수집하고 모니터링할 것인가? 로그는? 시스템은 어떻게 배포해 나갈 것인가?
미래에 닥칠 규모 확장 요구에 어떻게 대처할 것인지도 흥미로운 주제다. 예를 들어, 현재 설계로 백만 사용자는 능히 감당할 수 있다고 해보자. 천만 사용자를 감당하려면 어떻게 해야 하는가?
시간이 좀 남았다면, 필요하지만 다루지 못했던 세부적 개선사항들으 제안할 수 있다.
이제 마지막으로 해야할 것과 하지말아야 할 것 을 정리해보자.
해야할 것
질문을 통해 보다 완벽하게 확인해라. 스스로 내린 가정이 옳다 믿고 진행하지마라.(절대로)
문제의 요구사항을 이해하라.
정답이나 최선의 답안 같은 것은 없다는 점을 명심하라.
면접관이 면접자의 사고 흐름을 이해할 수 있도록 하라. (소통)
가능하다면 여러 해법을 함께 제시해라.
개략적 설계에 면접관이 동의하면, 각 컴포넌트의 세부사항을 설명하기 시작하라. 가장 중요한 컴포넌트부터 진행.
놀이터에 시소가 있다. 시소는 중심으로 부터 2, 3, 4m 거리의 지점에 좌석이 하나씩 있다.
각 사람마다 무게가 존재하고 거리 X 사람의 무게가 같다면 시소 짝꿍이 될 수 있다.
입력
int 배열 weights가 주어지며 길이는 2이상 10만 이하이다.
weights[i]는 100이상 1000이하이다.
풀이
문제를 정확하게 풀어내기 위해서는 완탐으로 10만 X 10만의 시간복잡도가 처음으로 생각날 것이다. 하지만, 10만X10만은 문제를 많이 풀어보면 알겠지만 완탐으로 시간초과가 나오기 아주 좋은 숫자이다. 보통 O(N^2)로 풀어낼 때, N이 10만이상이면 시간을 줄일 생각을 먼저해야한다.
그렇다면, 어떻게 시간을 줄일까? 제한 사항을 읽어보며, weights[i]의 숫자가 문제를 풀어낼 수 있는 key임을 알 수 있었다. weights 배열을 한바퀴 돌며, 100에서 1000사이의 값의 개수를 구한 뒤 100~1000사이를 돌면 끝나는 문제였다. 이대로 구현하면 문제는 크게 O(N+900)으로 O(N)만에 문제를 풀어낼 수 있다.
오답 코드
class Solution {
public long solution(int[] weights) {
long answer = 0;
int[] arr = new int[1001];
for(int i = 0; i < weights.length; i++) {
arr[weights[i]]++;
}
long[] sameNumber = new long[100001];
sameNumber[0] = 0;
sameNumber[1] = 0;
for(int i = 2; i <= 100000; i++) {
sameNumber[i] = (sameNumber[i-1]+(i-1));
}
for(int i = 100; i <= 1000; i++) {
if(arr[i] == 0) continue;
answer += sameNumber[(int)arr[i]];
double divideOfTwo = i/2.0;
double divideOfThree = i/3.0;
if(divideOfTwo*3 <= 1000) {
if(isInteger(divideOfTwo*3)) {
answer += (arr[i]*arr[(int)(divideOfTwo*3)]);
}
}
if(divideOfTwo*4 <= 1000) {
if(isInteger(divideOfTwo*4)) {
answer += (arr[i]*arr[(int)(divideOfTwo*4)]);
}
}
if(divideOfThree*4 <= 1000) {
if(isInteger(divideOfThree*4)) {
answer += (arr[i]*arr[(int)(divideOfThree*4)]);
}
}
}
return answer;
}
public boolean isInteger(double num) {
return Math.floor(num) == num;
}
}
풀이대로 구현했지만 3개의 답안이 통과되지 못했다. 약 30분을 고민하며 코드를 살펴본 결과 답을 알 수 있었다. 문제는 아래에 있었다.
int[] arr = new int[1001];
int형 배열로 선언한 것이 무엇이 문제일까? 아래를 보고선 힌트를 얻어보자.
answer += (arr[i]*arr[(int)(divideOfTwo*3)]);
문제가 무엇인지 알 수 있을까? 모르겠다면 조금 더 고민해보자.
정답은 arr[i]가 5만 arr[(int)(divideOfTwo*3)]가 5만이라고 생각해보자. 곱하면 25억이 나오지만 int형은 21억까지만 표현할 수 있기때문에 쓰레기 값이 나오게된다. 해결방법은 arr배열을 long타입으로 선언하면 된다.
정답 코드
class Solution {
public long solution(int[] weights) {
long answer = 0;
long[] arr = new long[1001];
for(int i = 0; i < weights.length; i++) {
arr[weights[i]]++;
}
for(int i = 100; i <= 1000; i++) {
if(arr[i] == 0) continue;
answer += (arr[i]-1)*arr[i]/2;
double divideByTwo = i/2.0;
double divideByThree = i/3.0;
if(divideByTwo*3 <= 1000) {
if(isInteger(divideByTwo*3)) {
answer += (arr[i]*arr[(int)(divideByTwo*3)]);
}
}
if(divideByTwo*4 <= 1000) {
if(isInteger(divideByTwo*4)) {
answer += (arr[i]*arr[(int)(divideByTwo*4)]);
}
}
if(divideByThree*4 <= 1000) {
if(isInteger(divideByThree*4)) {
answer += (arr[i]*arr[(int)(divideByThree*4)]);
}
}
}
return answer;
}
public boolean isInteger(double num) {
return Math.floor(num) == num;
}
}
!TIP 추가로 sameNumber 배열은 같은 수일 때 짝꿍 개수를 얻기 위해 dp형식으로 만들었지만, (n-1)*n/2로 표현할 수 있음을 이후에 알게되어 고쳤다.
시스템 용량이나 성능 요구사항을 개략적으로 추정하는 것은 성능 수치상에서 사고 실험을 행하여 추정치를 계산하는 행위이다. 이를 통해 어떤 설계가 요구사항에 부합할 것인지 알 수 있다. 이러한 개략적인 규모 추정을 효과적으로 해 내려면 규모 확장성을 표현하는 데 필요한 기본기에 능숙해야 한다. 특히, 2의 제곱수나 응답지연 값, 가용성에 관계된 수치들을 기본적으로 잘 이해하고 있어야한다.
2의 제곱수
데이터 볼륨의 단위를 2의 제곱수로 표현하면 어떻게 되는지 알아야 제대로된 결과를 얻을 수 있다. 최소 단위는 1바이트이고, 8비트로 구성된다. ASCII 문자 하나가 차지하는 메모리 크기가 1바이트다. 아래는 흔히 쓰이는 데이터 볼륨 단위들이다.
2의 x 제곱
근사치
이름
축약형
10
1천
1 KiloByte
1KB
20
1백만
1 MegaByte
1MB
30
10억
1 GigaByte
1GB
40
1조
1 TeraByte
1TB
50
1000조
1 PetaByte (페타바이트)
1PB
모든 프로그래머가 알아야 하는 응답지연 값
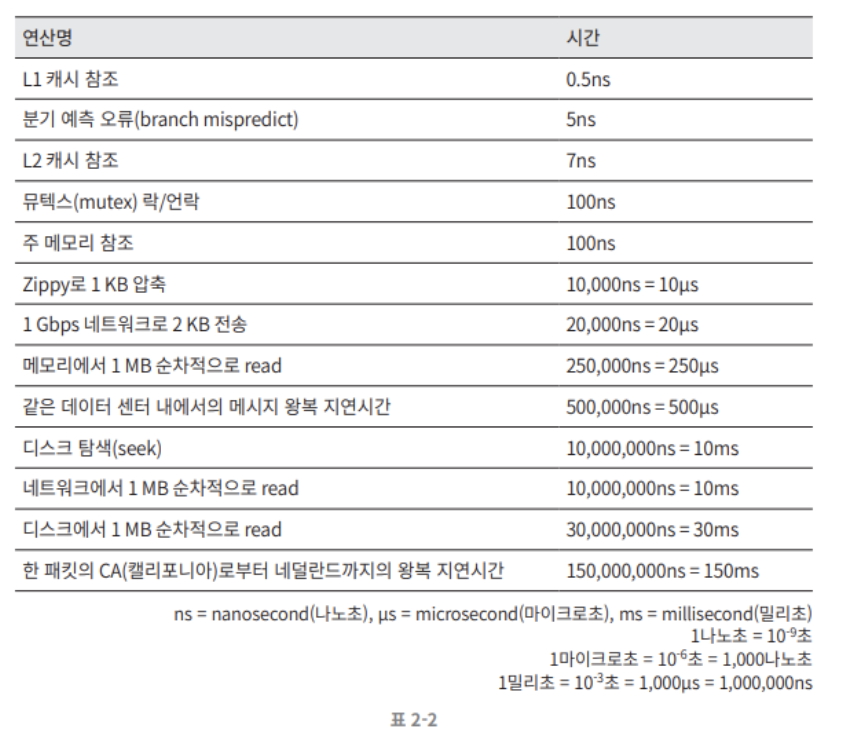
구글의 제프 딘은 2010년에 통상적인 컴퓨터에서 구현된 연산들의 응답지연 값을 공개한 바 있다. 이들 중 몇몇은 더 빠른 컴퓨터가 등장하면서 유효하지 않게 되었지만, 어느정도 짐작할 수 있도록 도와준다.
이 수들을 알기 쉽게 시각화한 자료는 아래와 같다. 아래는 2020년 기준으로 시각화한 수치이다.
제시된 수치들을 분석하면 아래와 같은 결론이 나온다.
메모리는 빠르지만 디스크는 아직도 느리다.
디스크 탐색은 가능한 한 피하자.
단순한 압축 알고리즘은 빠르다.
데이터를 인터넷으로 전송하기 전에 가능하면 압축하라.
데이터 센터는 보통 여러 지역에 분산되어 있고, 센터들 간에 데이터를 주고 받는데는 시간이 걸린다.
가용성에 관계된 수치들
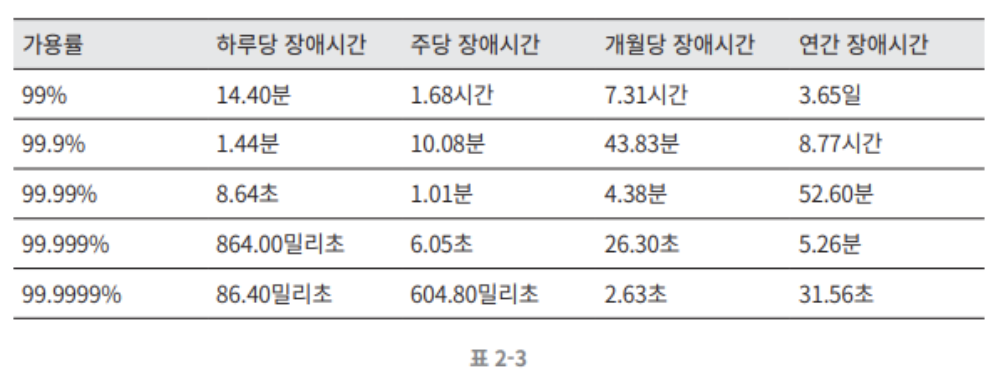
고가용성은 시스템이 오랜 시간 동안 지속적으로 중단 없이 운영될 수 있는 능력을 지칭하는 용어다. 고가용성을 표현하는 값을 percent로 표현하는데, 100%는 시스템이 단 한번도 중단된 적이 없었음을 의미한다. 대부분의 서비스는 99~100% 사이의 값을 갖는다.
SLA는 서비스 사업자가 보편적으로 사용하는 용어로, 서비스 사업자와 고객 사이의 맺어진 합의를 의미한다. 이 합의에는 서비스 사업자가 제공하는 서비스의 가용시간이 공식적으로 기술되어 있다. AWS, Google, Microsoft 같은 사업자는 99% 이상의 SLA를 제공한다.
예제: 트위터 QPS와 저장소 요구량 추정
가정
월간 능동 사용자는 3억명이다.
50%의 사용자가 트위터를 매일 사용한다.
평균적으로 각 사용자는 매일 2건의 트윗을 올린다.
미디어를 포함하는 트윗은 10% 정도이다.
데이터는 5년간 보관된다.
추정
QPS 추정치
일간 능동 사용자 = 3억 x 50% = 1.5억
QPS = 1.5억 x 2트윗/24시간/3600초 = 약 3500
최대 QPS = 2 x QPS = 약 7000
미디어 저장을 위한 저장소 요구량
평균 트윗 크기
tweet_id에 64바이트
텍스트에 140바이트
미디어에 1MB
미디어 저장소 요구량 = 1.5억 x 2 x 10% x 1 B = 30TB/일
5년간 미디어를 보관하기 위한 저장소 요구량: 30TB x 365 x 5 = 약 55PB
팁
개략적인 규모 추정과 관계된 면접에서 가장 중요한 것은 문제를 풀어나가는 절차다. 올바른 절차를 밟느냐가 결과는 내는 것보다 중요하다. 면접관이 보고 싶어하는 것은 면접자의 문제 해결 능력이다. 아래 몇 가지 팁을 참고해보자.
근사치를 활용한 계산
면접장에서 복잡한 계산을 하는 것은 어려운 일이다. 계산 결과의 정확함을 평가하는 것이 목적이 아니므로, 적절한 근사치를 활용하여 계산을 간단화하는 것이 좋다.
가정을 적어두자. 나중에 살펴볼 수 있도록
단위를 붙여라
5라고만 적어놓으면 5KB인지 5MB인지 알 수가 없다. 나중에 헷갈리게 될 수 있으므로 단위를 붙이는 습관을 들이자.
많이 출제되는 개략적 규모 추정 문제는 QPS, 최대 QPS, 저장소 요구량, 캐시 요구량, 서버 수 등을 추정하는 것이다.